GTC 2026 Keynote — Part 2: Intro, Analytics, CUDA-X & Inference
This is Part 2 of a 3-part breakdown of the GTC 2026 keynote. Start with Part 1: Overview & Context or jump to Part 3: Vera Rubin Hardware, OpenClaw & Robotics. The single-page version is also available.
Previously in Part 1: I covered the conference’s atmosphere, shared a bit about the keynote’s energy, NVIDIA’s celebration of CUDA’s 20th anniversary and the flywheel it has created, and how the introduction of the new Groq rack expended NIVDIA’s AI Factory Pod, now a five-rack system combining the Groq LPX, BlueField-4, Vera CPU, and Spectrum-6 networking racks alongside the Vera Rubin GPU node.
Summary of Part 2 sections
Here’s a short breakdown of the first hour of the Keynote. For each of the section i give how much time Jensen spent on it along with my impressions and summary notes. I also link directly into each section on the YouTube video.
| Duration | Section |
|---|---|
| 16 min | Intro, Cuda flywheel, Graphics improvements — Celebrating Cuda’s 20y anniversary and showing DLSS5 graphics improvements |
| 22 min | Accelerated Analytics — Emphasizing NVIDIA’s role in accelerating enterprise analytics and many of the CSP’s AI offerings in the agentic era |
| 7 min | Cuda-X review and AI native companies — Reviewing the library ecosystem that forms CUDA-X |
| 22 min | AI Inference Inflection + Datacenter efficiency overview — Discussing the AI inference inflection point and how CEO’s will be evaluating their agentic companies |
Intro, Cuda flywheel, Graphics improvements (16min)
| Tokens, the Building Blocks of AI · 3:15min |
| The keynote starts with an inspiring video describing how AI tokens are the main "commodity" produced by AI factories and their power to unlock new knowledge and possibilities |
| Welcome to GTC 2026 · 2:47min |
| Jensen enters the stage and gives introductory remarks thanking the pre-game show hosts, and also how the conference will be covering the AI 5 layer cake, a reference to his blog post that divides the stack along: Energy, Chips, Infrastructure, Models, and Applications |
| 20 Years of CUDA · 4:21min |
Jensen reviews the flywheel that Cuda software has been enabling for the past 20 years.  |
| GeForce · 3:27min |
| CUDA made GPUs programmable first on the consumer product GeForce in 2006, which then enabled the deep learning community to test the viability of training neural networks and launched the new AI revolution. |
| DLSS 5 · 2:29min |
Jensen shows a video featuring the new DLSS5 capability, a Neural rendering technology that fuses 3d Graphics with AI to give more beautiful and detailed textures to videos. Video details triggered a backlash from game developers.  |
Accelerated Analytics (22min)
| Structured Data is the Ground Truth of AI · 3:26min |
| Jensen says Analytics are ripe for acceleration with the arrival of AI agent and emphasizes CuDF and CuVS as foundation libraries powering the whole ecosystem. |
| IBM Reinvents Data Processing With NVIDIA · 18:10min |
He announced partnerships with IBM for Watson-X, a major contributed to open source Presto C++ and user of Spark over Rapids, NVIDIA's own accelerated dataframe libraries. Also announced were partnerships with Dell for an AI platform over RTX6000 servers, and for Google Cloud's AI Hypercomputer. Jensen highlights NVIDIA's stack that accelerate many of the CSP's offerings for AI and he spent some time reviewing them for different cloud providers. 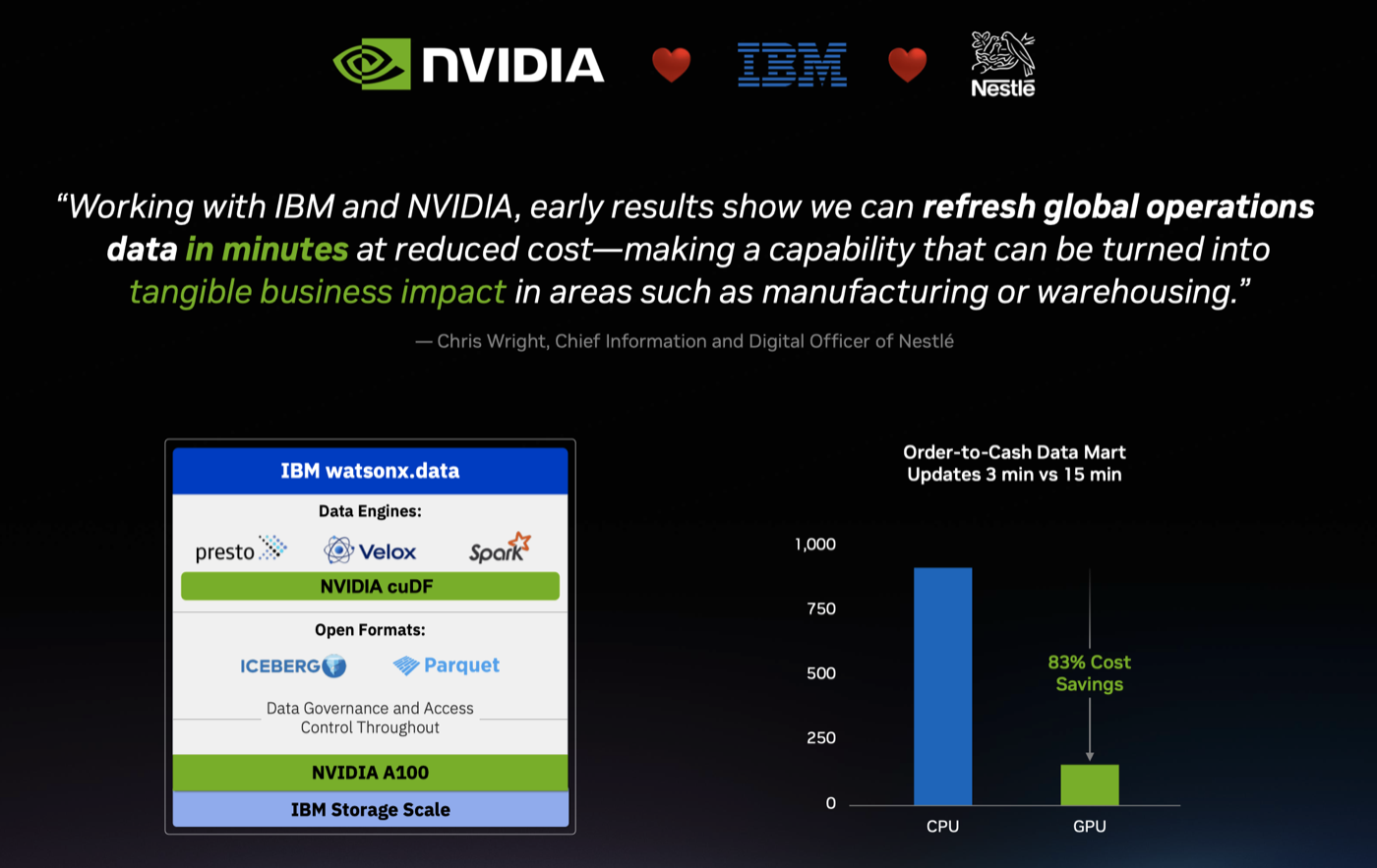 |
Cuda-X review and AI native companies (7min)
| NVIDIA Foundational Technology Montage · 4:44min |
| Jensen does a quick review of the list of cuda-x libraries and shows a video simulation of these libraries at work |
| AI Natives · 2:46min |
| The number of AI native companies has exploded in the past year with $150B VC investments. They all need token compute that NVIDIA can provide. |
AI Inference Inflection + Overview of datacenter efficiency (Tokens/Watt) vs interactivity (Tokens/s per user) across different tiers (22min)
| Inference Inflection Arrives · 4:42min |
Jensen highlights 3 key moments for AI inference in the past 2 years: 2023) ChatGPT is released 2024) reasoning AI model with o1 and o3 takeoff and in 2025) Claude code agentic system revolutionizes software engineering. 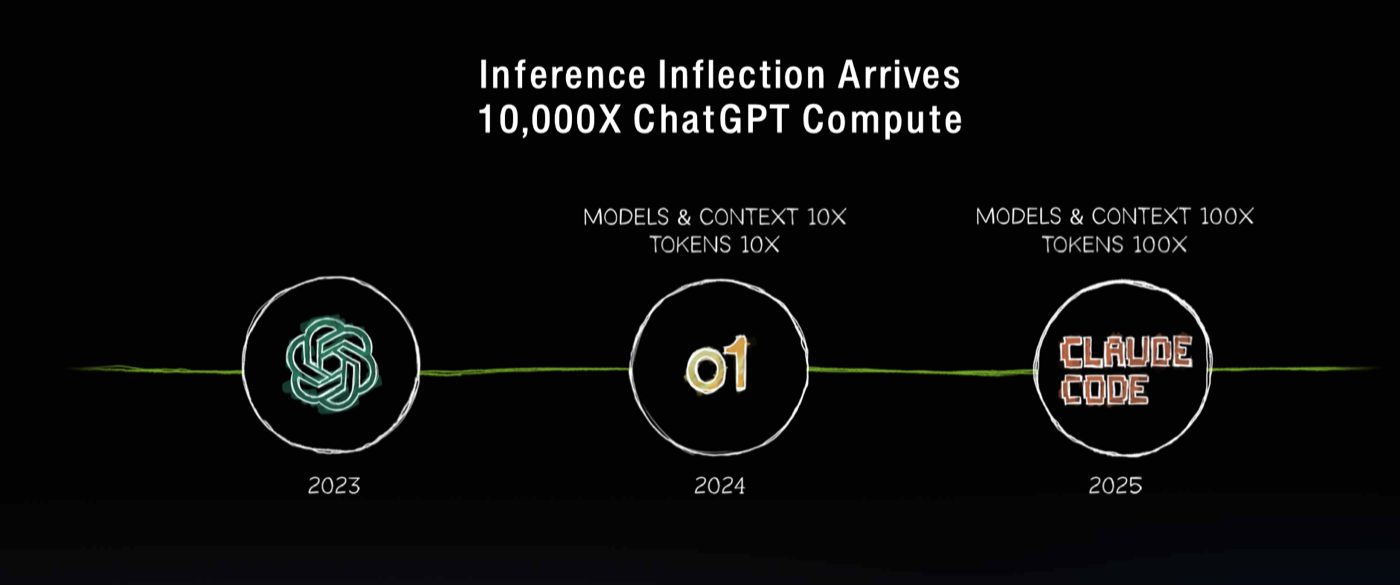 |
| "The inflection point for inference has arrived." · 1:40min |
| Agent thinking capabilities led to an explosion in the amount of inference by 10,000x since ChatGPT was released. Coupled with 100x increase in end-user demand, Jensen says we have 1M x more inference demand since 2023. We are now at an inflection point for inference |
| Inference Inflection Drives Strong Growth · 8:30min |
Last year Jensen saw $500B demand for blackwell. This year through 2027, he see $1Tr in infrastructure investments on NVIDIA mainly for inference. 60% of the business is for hyperscalers (some of it for internal use), and 40% is all the rest, such as regional or sovereign cloud, enterprise, supercomputers and all the rest. GB + NVL72 + inference over fp4 for training, dynamo, tensorRT. DGX Cloud. 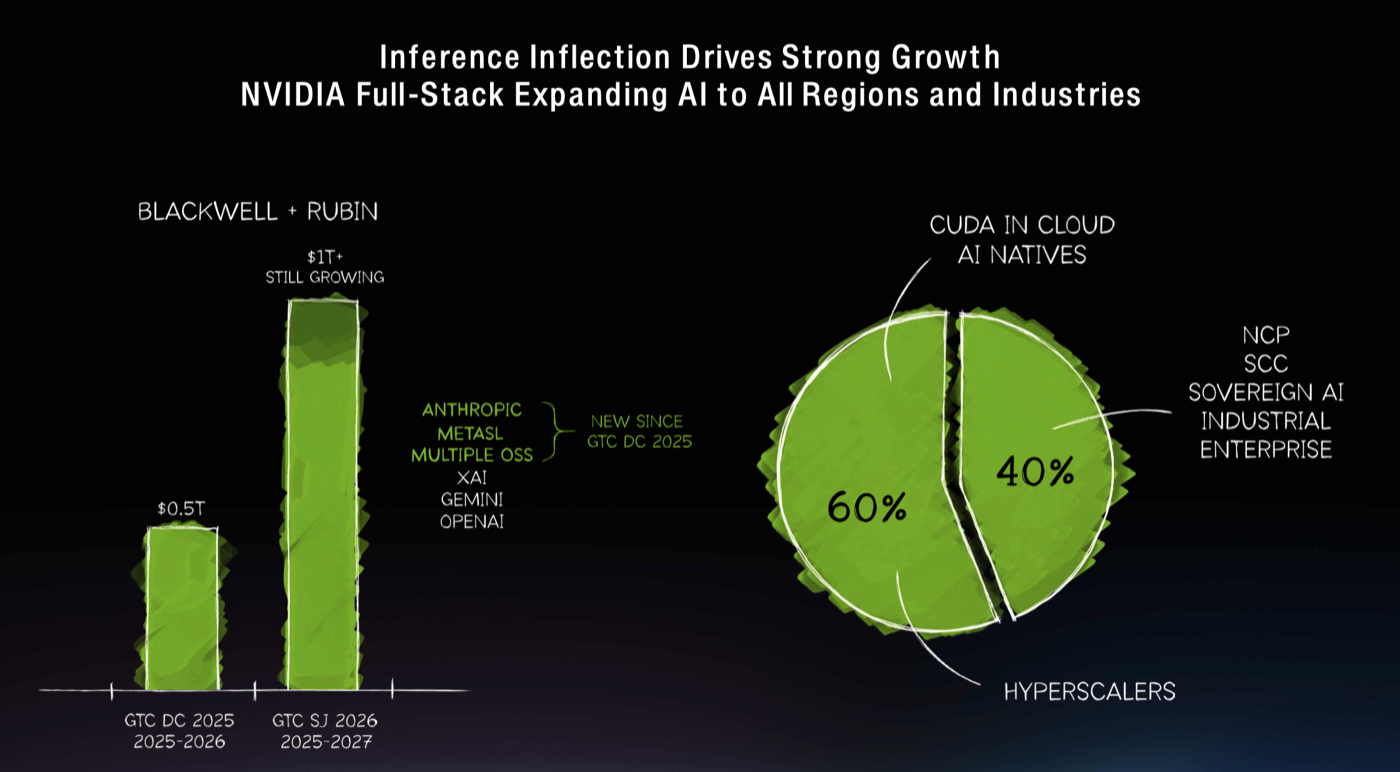 |
| NVIDIA Extreme Co-Design Revolutionized Token Cost · 3:57min |
Datacenters are constrained by a fixed amount of power (Watts) available. Emphasize Tokens Per Watt as the metric to maximize, and interactivity (token/s per User) as a use case differentiator. 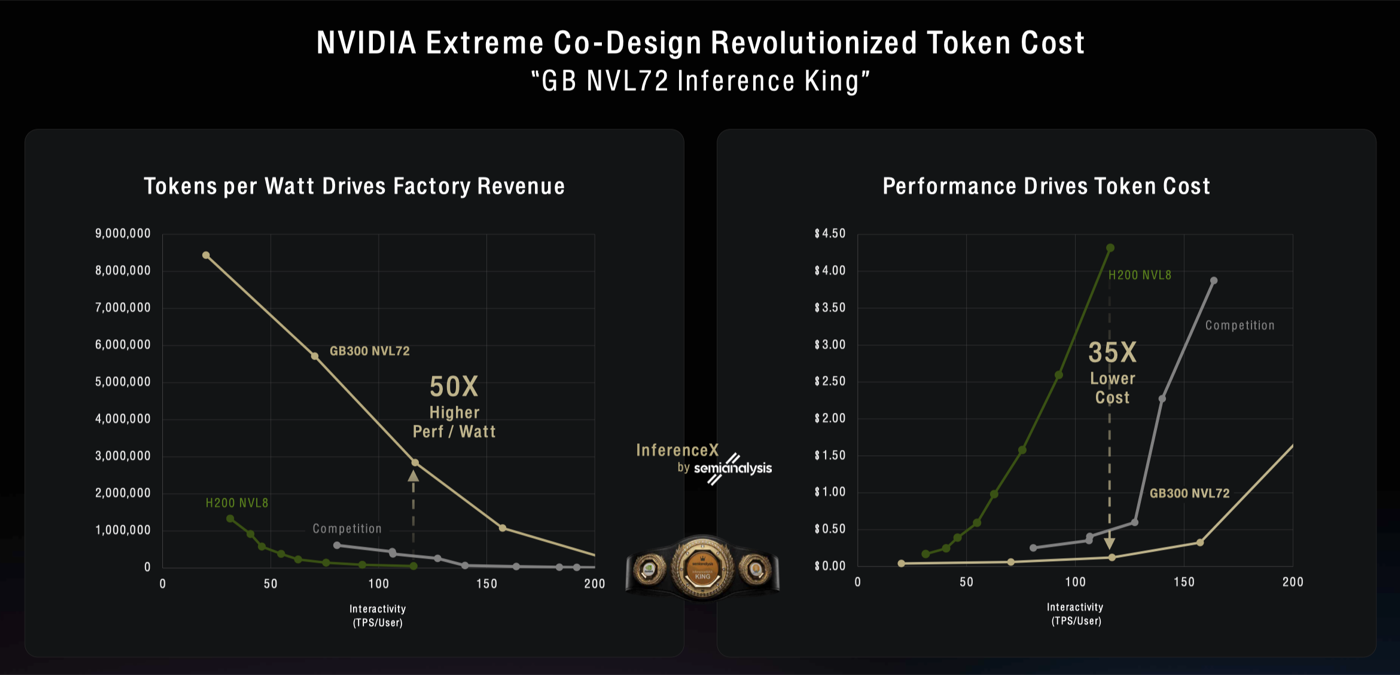 |
| InferenceMAX King · 1:23min |
| Shows how GB300NVL72 has improved on both efficiency and cost for inference and has been recognized by semianalysis as inference King! |
| NVIDIA is the Global Standard for AI Inference at Scale · 0:33min |
| Inference service providers should be seen as token factories. The output token rate from companies like eigen AI, together.ai, nebius, etc. has increased very fast, now reaching 400+ token/s for kimiK2.5 reasoning agent. Also see artificial analysis for a breakdown between providers. |
| AI Factories are the Industrial Infrastructure of the AI Era · 1:10min |
| Inference drives revenues and Token effectiveness is the most important metric. |
The first hour of the keynote established the foundations: CUDA’s flywheel, NVIDIA’s growing role in enterprise analytics, and the massive scale of the inference inflection. Part 3 shifts to the hardware itself where Jensen walks through the full Vera Rubin stack with Groq, then turns to what he called one of the most important open source moments in history.
← Part 1: Overview & Context · Part 3: Vera Rubin Hardware, OpenClaw & Robotics →