GTC 2026 Keynote — Part 1: Overview & Context
This is Part 1 of a 3-part breakdown of the GTC 2026 keynote. Jump to Part 2: Intro, Analytics, CUDA-X & Inference or Part 3: Vera Rubin Hardware, OpenClaw & Robotics. The single-page version is also available.
I was back this year for the 2026 edition of NVIDIA’s GTC conference held at the San Jose Convention Center and surroundings from March 16-19.

Like last year, there was plenty of energy at the conference with attendee numbers said to have reached more than 30k. The conference was packed with interesting technical sessions on new developments in the NVIDIA ecosystem including technical sessions on CUDA-X libraries and industry and state partners presenting how they have integrated the NVIDIA stack into their products.
The conference expanded to the nearby hotels for additional space, the security check-ins were moved out of the convention center and onto the street and an additional lunch section was added in the parking lot in front of the Hylton Hotel on S. Almaden Road.
Finally the keynote was held like previous years at the SAP Center, a 15min walk away, with a larger pavilion setup just outside of it for free coffee and pastries and for hosting the “pre-game” show featuring executives and technical leaders of companies working with NVIDIA. Other than that, the conference looks about the same as last year!
In this post, I will only cover the keynote and will delve into the sessions I attended and the exhibit hall in followup posts.
The Keynote
The keynote was the main event held on the first day of conference and it was moved ahead to 11AM, making it easier to get there early and avoid long lines. Here are some pictures from the packed SAP Center stadium where it was held


As he does every year, Jensen showed hardware on stage, including the new Vera Rubin tray, the new Groq LPX tray, and the new Co-Packaged Optical switch tray for scaling up. He also showed Vera Ultra and its Kyber rack design where trays are inserted vertically instead of horizontally. The exhibit hall had all these nicely on display.




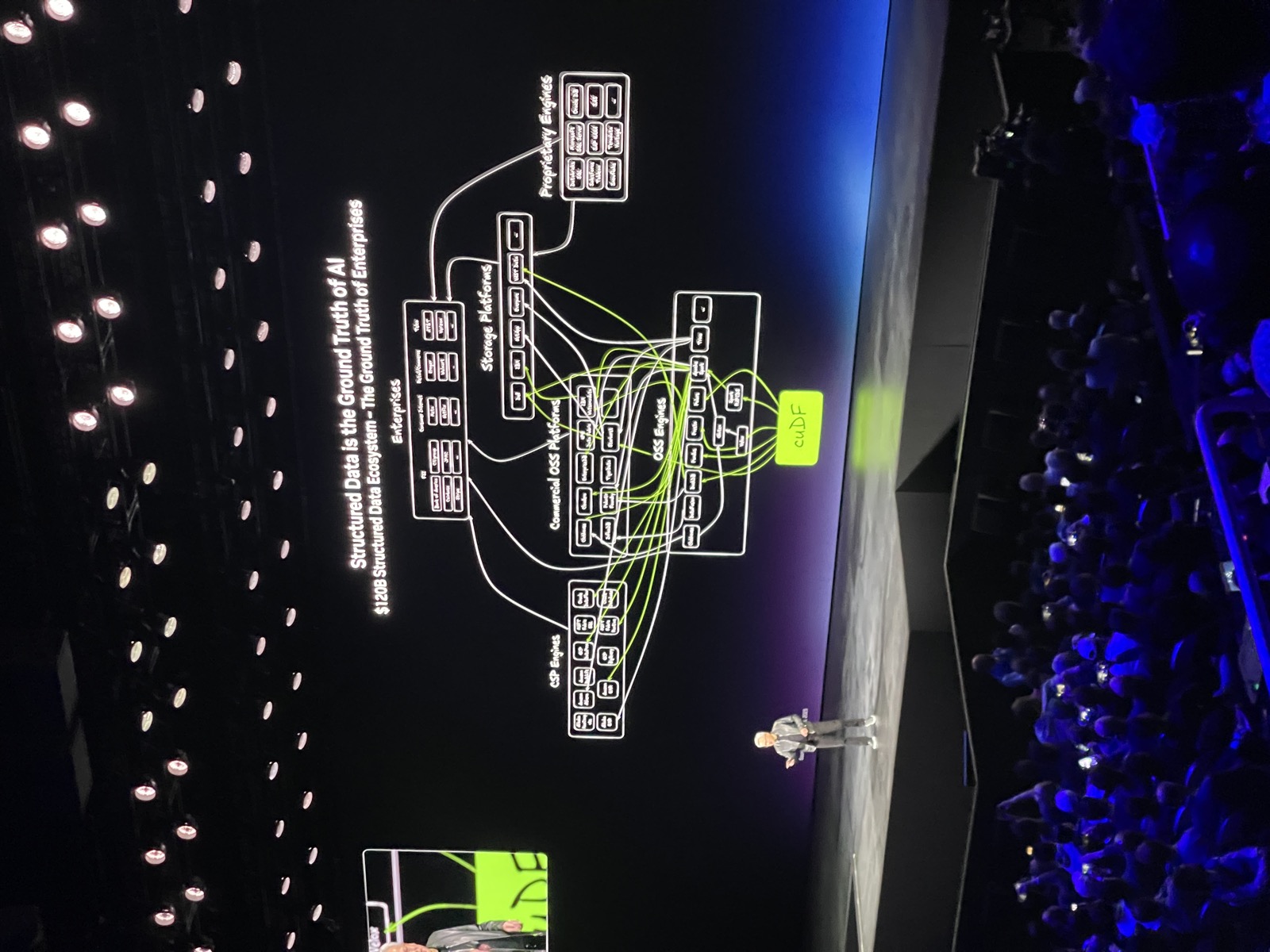
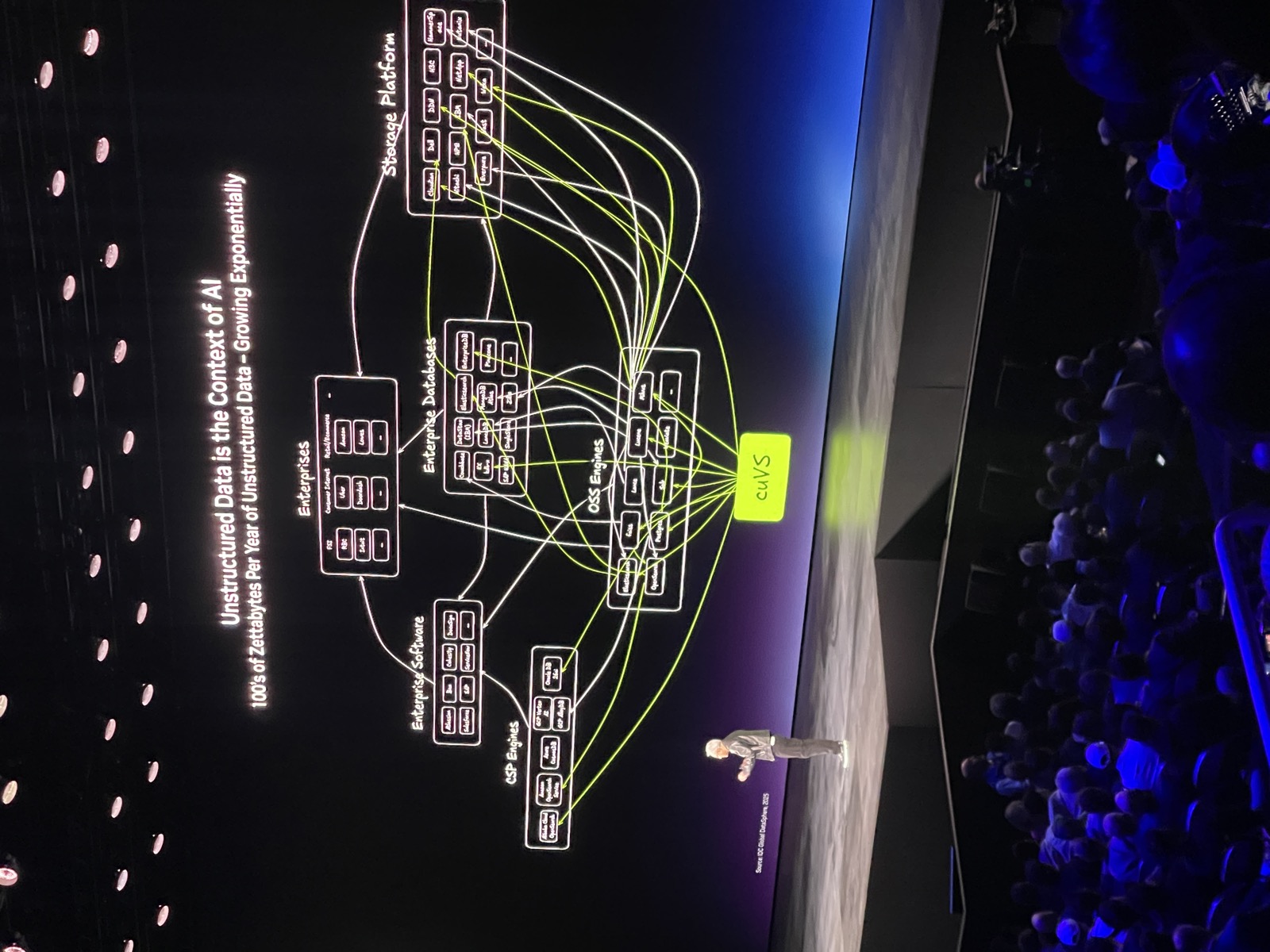
One interesting aspect I wasn’t expecting was Jensen spending 18 minutes almost at the outset of the keynote talking about how NVIDIA’s libraries are sitting at the foundation of accelerated analytics in Enterprise structured and unstructured data. He announced several partnerships with the cloud providers and highlighted how many of NVIDIA’s solutions accelerate CSP’s offerings. I will cover the analytics aspects of the conference in a separate post.
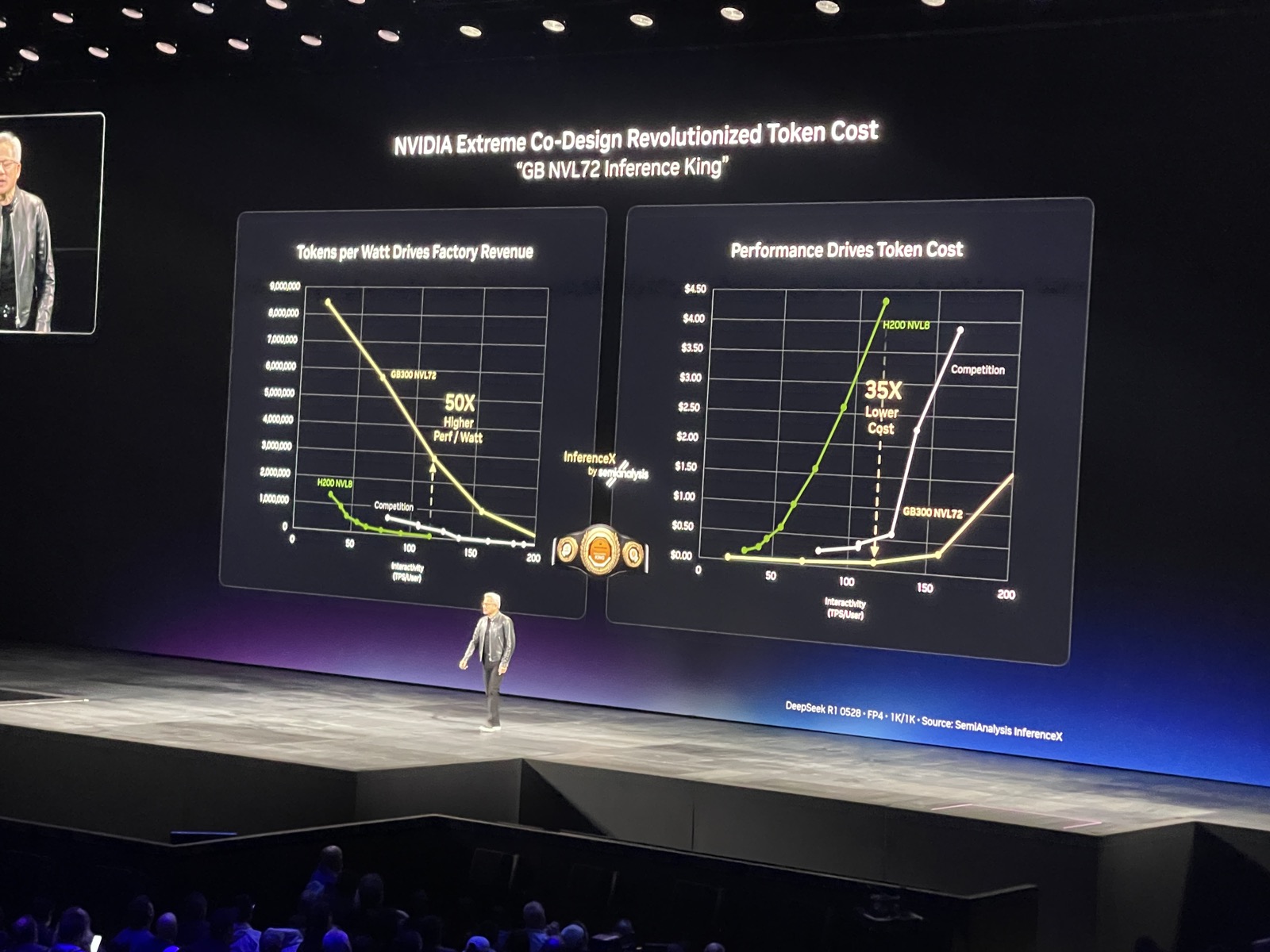
Jensen reveled in being crowned “inference king” by Semianalysis for GB NVL72 system! Also check their review1 of the GTC conference.
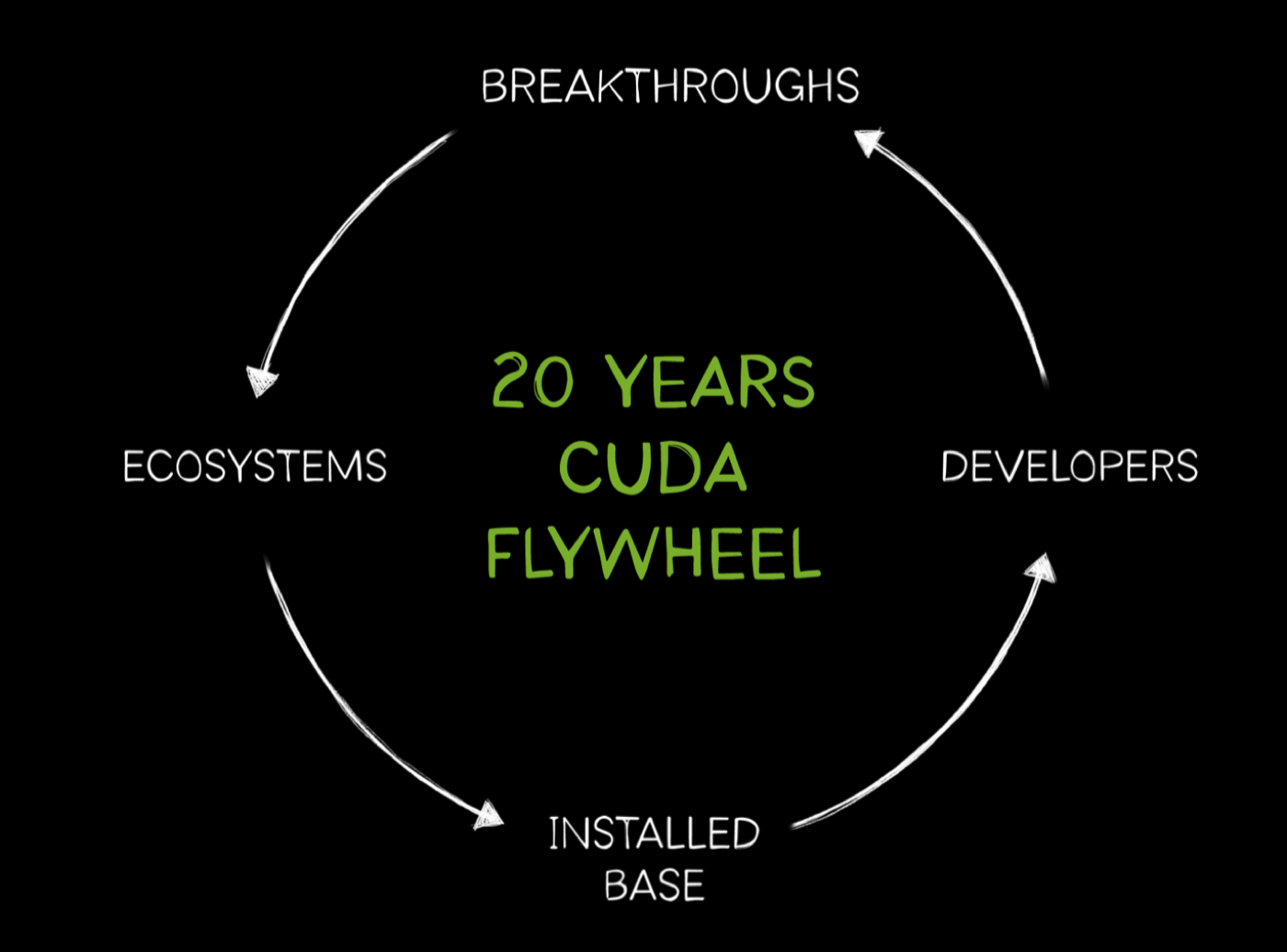
CUDA is 20 years old
CUDA is now 20 years old, and Jensen celebrated that by spending a few extra minutes talking about its core importance to NVIDIA as a company. He emphasized the crucial flywheel role that CUDA-X plays for NVIDIA as an ecosystem of hundreds of libraries for accelerating all kinds of workloads. As the install base for CUDA has grown, reaching hundreds of millions of GPUs deployed around the world, so has the reach to developers, leading to new breakthroughs in many domains, each creating new markets and new customers who then want to buy more GPUs, further growing the user base.
The Vera Rubin POD is expanding: Seven Chips, Five Rack-scale Systems
One of the major reveals at this year’s conference and worth re-emphasizing is the addition of the Groq LPU to speed up AI inference and the addition of co-packaged optics for the scale network. The NVIDIA AI factory is built around five rack types, and a full Vera Rubin POD “features 40 racks, 1.2 quadrillion transistors, nearly 20,000 NVIDIA dies, 1,152 NVIDIA Rubin GPUs, 60 exaflops, and 10 PB/s total scale-up bandwidth”2

- The VR NVL72 GPU node
- The newly announced companion Groq LPU rack offloading part of the AI inference pass (decode)
- BlueField-4 to store KV cache offloaded from the GPU memory
- Vera CPU Rack for more general Agentic workloads and RL, and
- the Spectrum-6 networking rack to connect the whole POD.
With the stage now set (the packed keynote venue, Jensen’s excitement about the expanding CUDA ecosystem, and the broad strokes of the new Vera Rubin POD), Part 2 dives into the actual keynote sections, starting with the CUDA anniversary, accelerated analytics, and Jensen’s case for the AI inference inflection point.
Part 2: Intro, Analytics, CUDA-X & Inference →
References
-
Semianalysis - Nvidia – The Inference Kingdom Expands — https://newsletter.semianalysis.com/p/nvidia-the-inference-kingdom-expands ↩
-
NVIDIA - Vera Rubin POD: Seven Chips, Five Rack-Scale Systems, One AI Supercomputer - https://developer.nvidia.com/blog/nvidia-vera-rubin-pod-seven-chips-five-rack-scale-systems-one-ai-supercomputer/ ↩