NVIDIA GTC 2026 Conference: The Keynote
Prefer a section-by-section breakdown? This keynote is also available as a 3-part series starting with Part 1.
I was back this year for the 2026 edition of NVIDIA’s GTC conference held at the San Jose Convention Center and surroundings from March 16-19.

Like last year, there was plenty of energy at the conference with attendee numbers said to have reached more than 30k. The conference was packed with interesting technical sessions on new developments in the NVIDIA ecosystem including technical sessions on CUDA-X libraries and industry and state partners presenting how they have integrated the NVIDIA stack into their products.
The conference expanded to the nearby hotels for additional space, the security check-ins were moved out of the convention center and onto the street and an additional lunch section was added in the parking lot in front of the Hylton Hotel on S. Almaden Road.
Finally the keynote was held like previous years at the SAP Center, a 15min walk away, with a larger pavilion setup just outside of it for free coffee and pastries and for hosting the “pre-game” show featuring executives and technical leaders of companies working with NVIDIA. Other than that, the conference looks about the same as last year!
In this post, I will only cover the keynote and will delve into the sessions I attended and the exhibit hall in followup posts.
The Keynote
The keynote was the main event held on the first day of conference and it was moved ahead to 11AM, making it easier to get there early and avoid long lines. Here are some pictures from the packed SAP Center stadium where it was held


As he does every year, Jensen showed hardware on stage, including the new Vera Rubin tray, the new Groq LPX tray, and the new Co-Packaged Optical switch tray for scaling up. He also showed Vera Ultra and its Kyber rack design where trays are inserted vertically instead of horizontally. The exhibit hall had all these nicely on display.




One interesting aspect I wasn’t expecting was Jensen spending 18 minutes almost at the outset of the keynote talking about how NVIDIA’s libraries are sitting at the foundation of accelerated analytics in Enterprise structured and unstructured data. He announced several partnerships with the cloud providers and highlighted how many of NVIDIA’s solutions accelerate CSP’s offerings. I will cover the analytics aspects of the conference in a separate post.
Jensen reveled in being crowned “inference king” by Semianalysis for GB NVL72 system! Also check their review1 of the GTC conference.
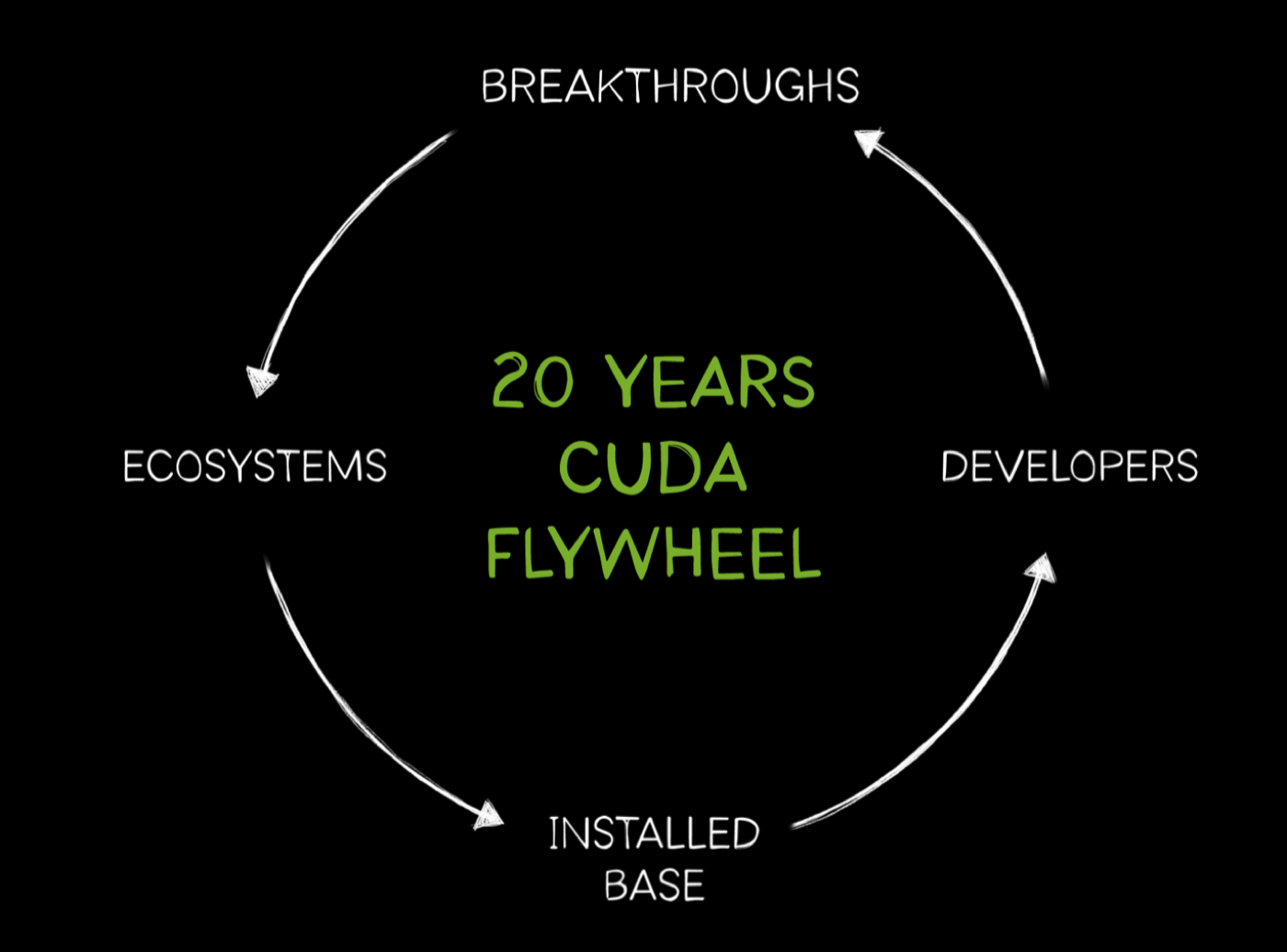
CUDA is 20 years old
CUDA is now 20 years old, and Jensen celebrated that by spending a few extra minutes talking about its core importance to NVIDIA as a company. He emphasized the crucial flywheel role that CUDA-X plays for NVIDIA as an ecosystem of hundreds of libraries for accelerating all kinds of workloads. As the install base for CUDA has grown, reaching hundreds of millions of GPUs deployed around the world, so has the reach to developers, leading to new breakthroughs in many domains, each creating new markets and new customers who then want to buy more GPUs, further growing the user base.
The Vera Rubin POD is expanding: Seven Chips, Five Rack-scale Systems
One of the major reveals at this year’s conference and worth re-emphasizing is the addition of the Groq LPU to speed up AI inference and the addition of co-packaged optics for the scale network. The NVIDIA AI factory is built around five rack types, and a full Vera Rubin POD “features 40 racks, 1.2 quadrillion transistors, nearly 20,000 NVIDIA dies, 1,152 NVIDIA Rubin GPUs, 60 exaflops, and 10 PB/s total scale-up bandwidth”2

- The VR NVL72 GPU node
- The newly announced companion Groq LPU rack offloading part of the AI inference pass (decode)
- BlueField-4 to store KV cache offloaded from the GPU memory
- Vera CPU Rack for more general Agentic workloads and RL, and
- the Spectrum-6 networking rack to connect the whole POD.
Summary of the Keynote by section
Here’s a short breakdown of the main section Jensen covered in the Keynote.
| Duration | Section |
|---|---|
| 16 min | Intro, Cuda flywheel, Graphics improvements — Celebrating Cuda’s 20y anniversary and showing DLSS5 graphics improvements |
| 22 min | Accelerated Analytics — Emphasizing NVIDIA’s role in accelerating enterprise analytics and many of the CSP’s AI offerings in the agentic era |
| 7 min | Cuda-X review and AI native companies — Reviewing the library ecosystem that forms CUDA-X |
| 22 min | AI Inference Inflection + Datacenter efficiency overview — Discussing the AI inference inflection point and how CEO’s will be evaluating their agentic companies |
| 38 min | Full Vera Rubin hardware stack + DSX platform — Showing Vera Rubin + Groq hardware and explaining how they improve the throughput vs. interactivity performance curves |
| 19 min | OpenClaw, NemoClaw, Open Model Coalition — Praising the explosive growth of OpenClaw as a revolutionary moment, and announcing NVIDIA’s enterprise reference NemoClaw and the open model coalition |
| 14 min | Robotics, Physical AI, & recap — Describing the evolution of physical AI and the robotic landscape and recaping with a specially generated music video |
Find the breakdown below, linking directly into each section on the YouTube video, along with summary notes and section durations.
Intro, Cuda flywheel, Graphics improvements (16min)
| Tokens, the Building Blocks of AI · 3:15min |
| Keynotes start with an inspiring video describing how AI tokens are the main "commodity" produced by AI factories and their power to unlock new knowledge and possibilities |
| Welcome to GTC 2026 · 2:47min |
| Jensen enters the stage and gives introductory remarks thanking the pre-game show hosts, and also how the conference will be covering the AI 5 layer cake, a reference to his blog post that divides the stack along: Energy, Chips, Infrastructure, Models, and Applications |
| 20 Years of CUDA · 4:21min |
| Jensen reviews the flywheel that Cuda software has been enabling for the past 20 years. |
| GeForce · 3:27min |
| CUDA made GPUs programmable first on the consumer product GeForce in 2006, which then enabled the deep learning community to test the viability of training neural networks and launched the new AI revolution. |
| DLSS 5 · 2:29min |
Jensen shows a video featuring the new DLSS5 capability, a Neural rendering technology that fuses 3d Graphics with AI to give more beautiful and detailed textures to videos. Video details triggered a backlash from game developers.  |
Accelerated Analytics (22min)
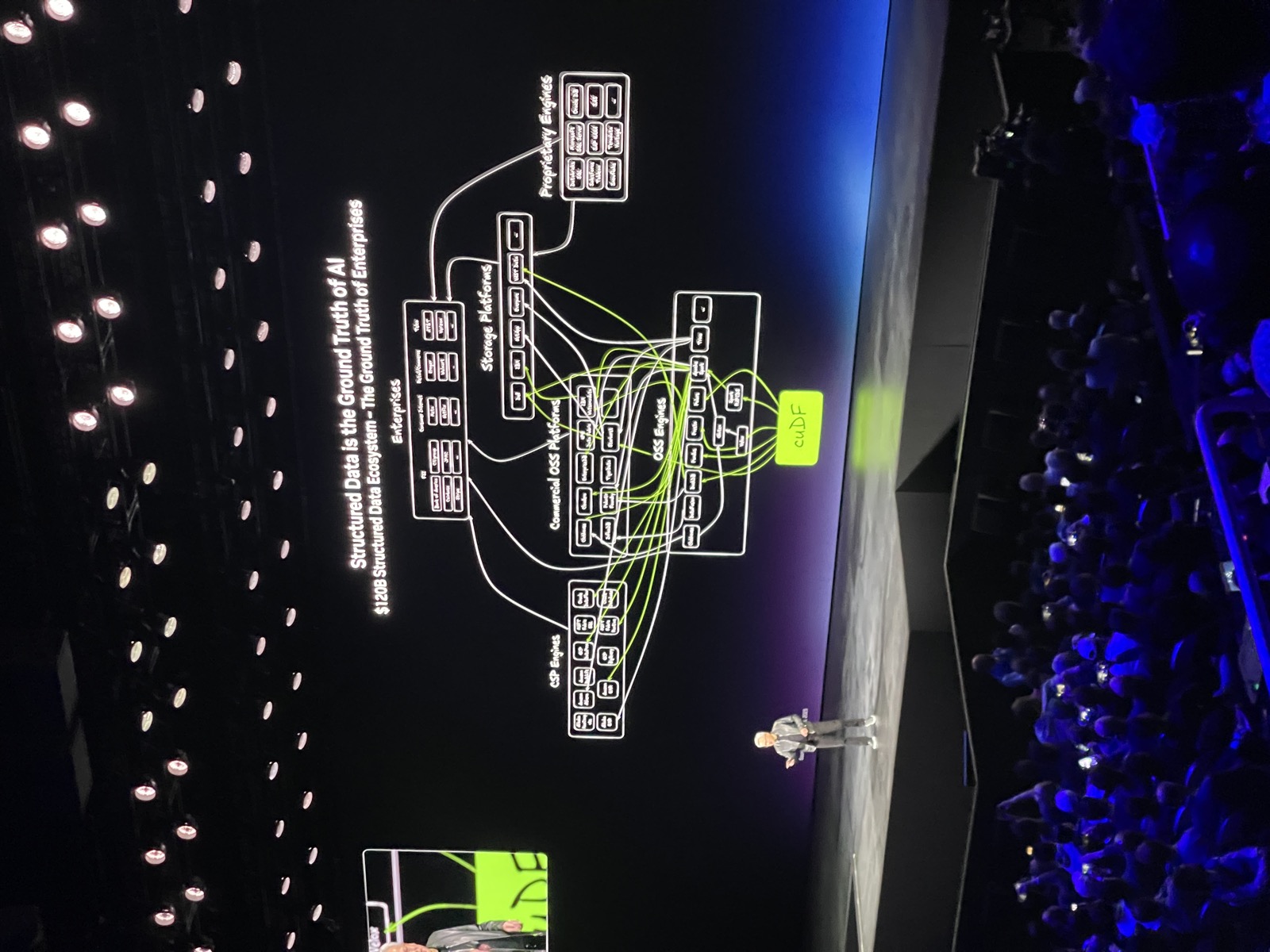
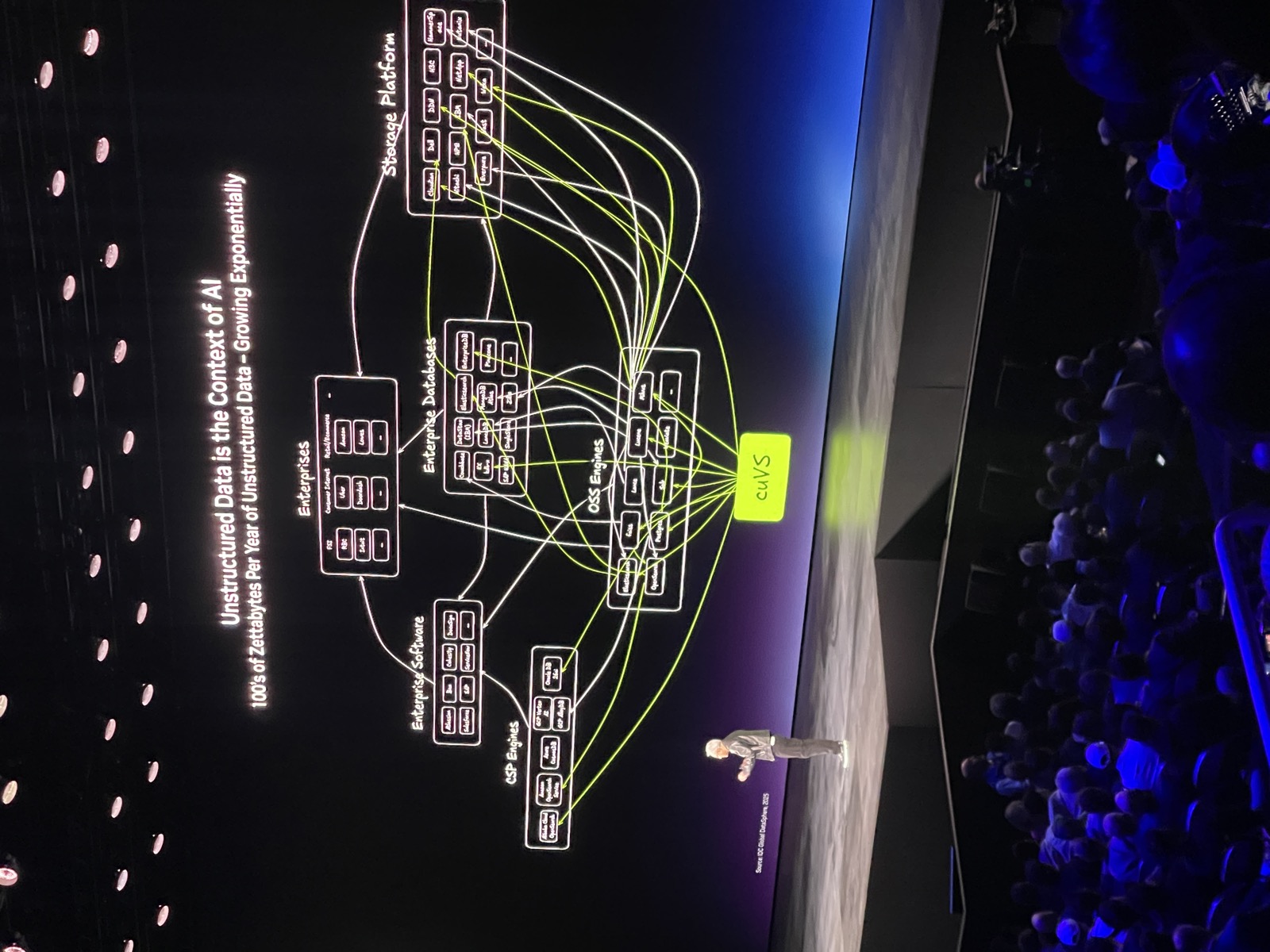
| Structured Data is the Ground Truth of AI · 3:26min |
| Jensen says Analytics are ripe for acceleration with the arrival of AI agent and emphasizes CuDF and CuVS as foundation libraries powering the whole ecosystem. |
| IBM Reinvents Data Processing With NVIDIA · 18:10min |
He announced partnerships with IBM for Watson-X, a major contributed to open source Presto C++ and user of Spark over Rapids, NVIDIA's own accelerated dataframe libraries. Also announced were partnerships with Dell for an AI platform over RTX6000 servers, and for Google Cloud's AI Hypercomputer. Jensen highlights NVIDIA's stack that accelerate many of the CSP's offerings for AI and he spent some time reviewing them for different cloud providers. 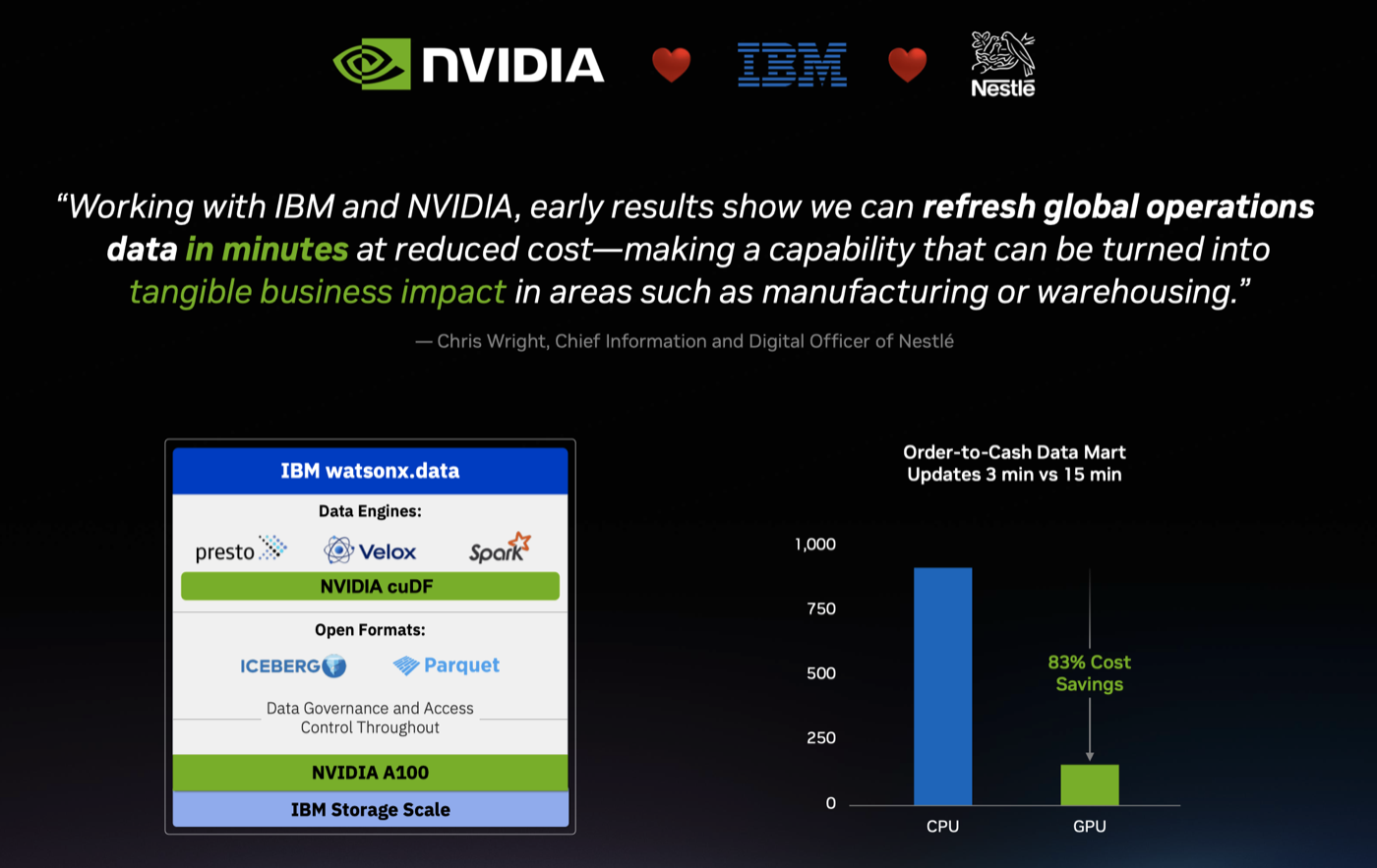 |
Cuda-X review and AI native companies (7min)
| NVIDIA Foundational Technology Montage · 4:44min |
| Jensen does a quick review of the list of cuda-x libraries and shows a video simulation of these libraries at work |
| AI Natives · 2:46min |
| The number of AI native companies has exploded in the past year with $150B VC investments. They all need token compute that NVIDIA can provide. |
AI Inference Inflection + Overview of datacenter efficiency (Tokens/Watt) vs interactivity (Tokens/s per user) across different tiers (22min)
| Inference Inflection Arrives · 4:42min |
Jensen highlights 3 key moments for AI inference in the past 2 years: 2023) ChatGPT is released 2024) reasoning AI model with o1 and o3 takeoff and in 2025) Claude code agentic system revolutionizes software engineering. 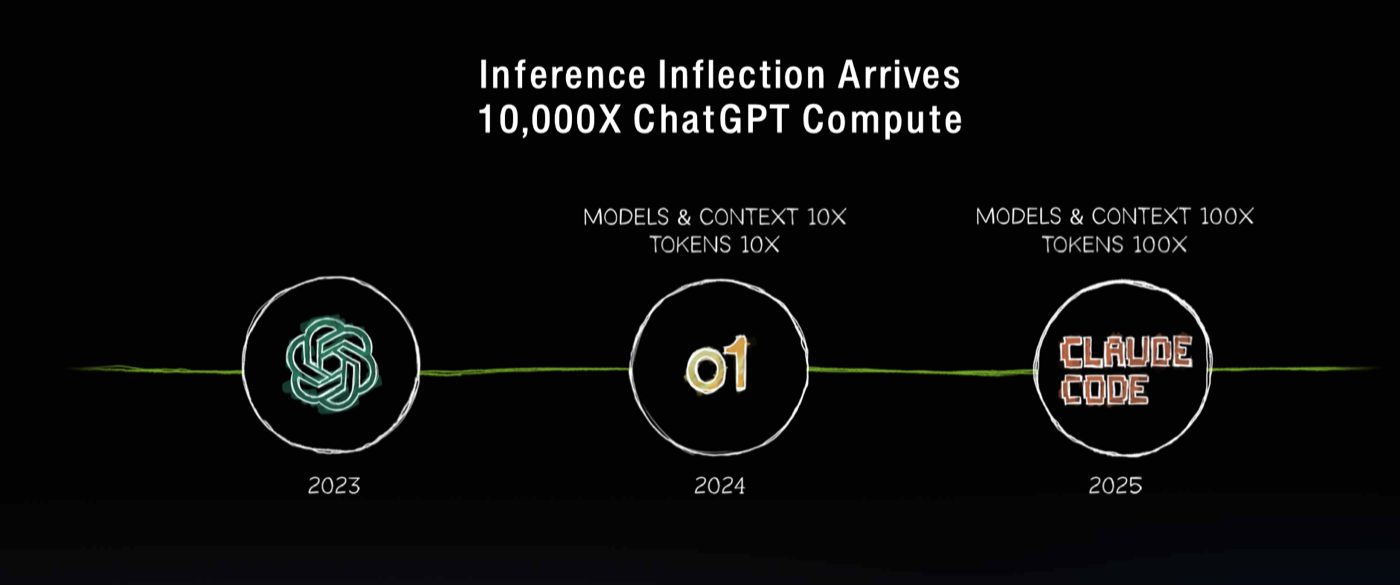 |
| "The inflection point for inference has arrived." · 1:40min |
| Agent thinking capabilities led to an explosion in the amount of inference by 10,000x since ChatGPT was released. Coupled with 100x increase in end-user demand, Jensen says we have 1M x more inference demand since 2023. We are now at an inflection point for inference |
| Inference Inflection Drives Strong Growth · 8:30min |
Last year Jensen saw $500B demand for blackwell. This year through 2027, he see $1Tr in infrastructure investments on NVIDIA mainly for inference. 60% of the business is for hyperscalers (some of it for internal use), and 40% is all the rest, such as regional or sovereign cloud, enterprise, supercomputers and all the rest. GB + NVL72 + inference over fp4 for training , dynamo, tensorRT. DGX Cloud. 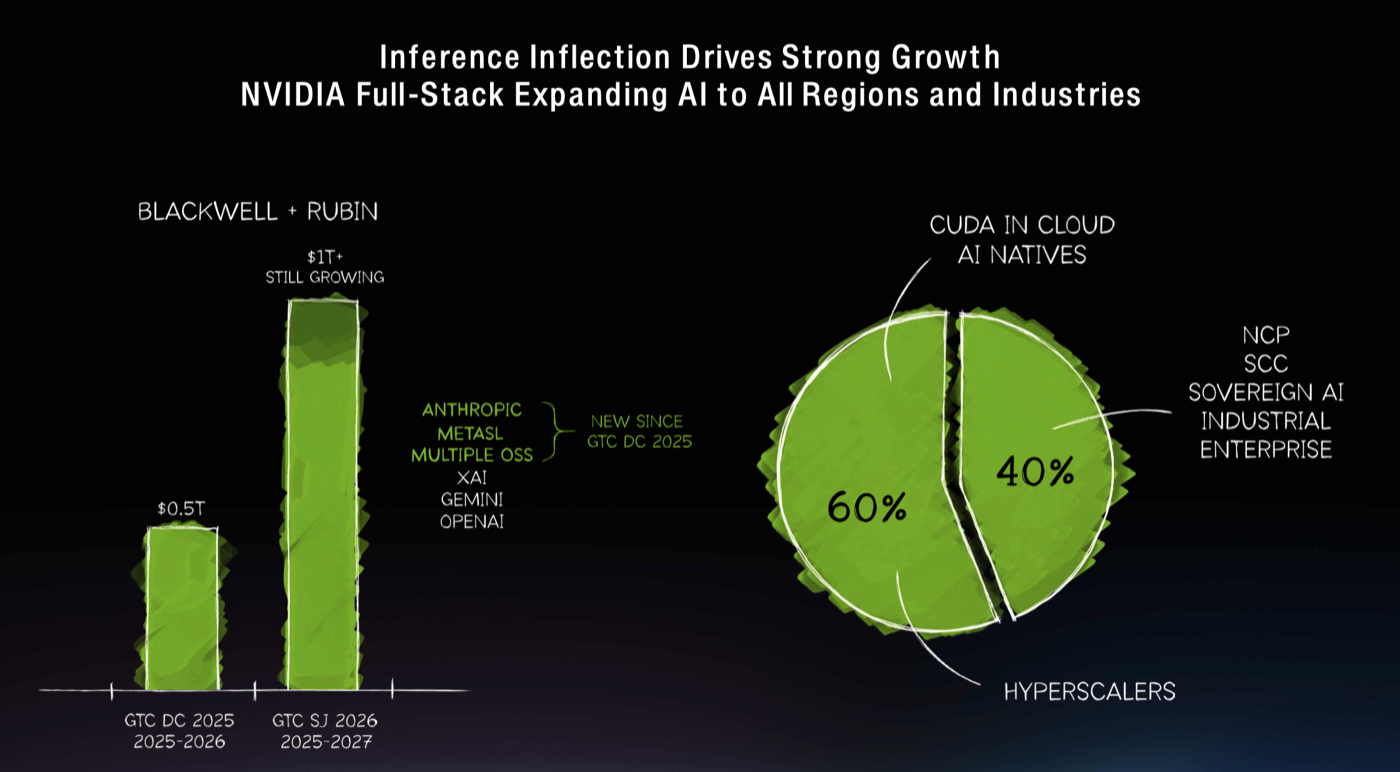 |
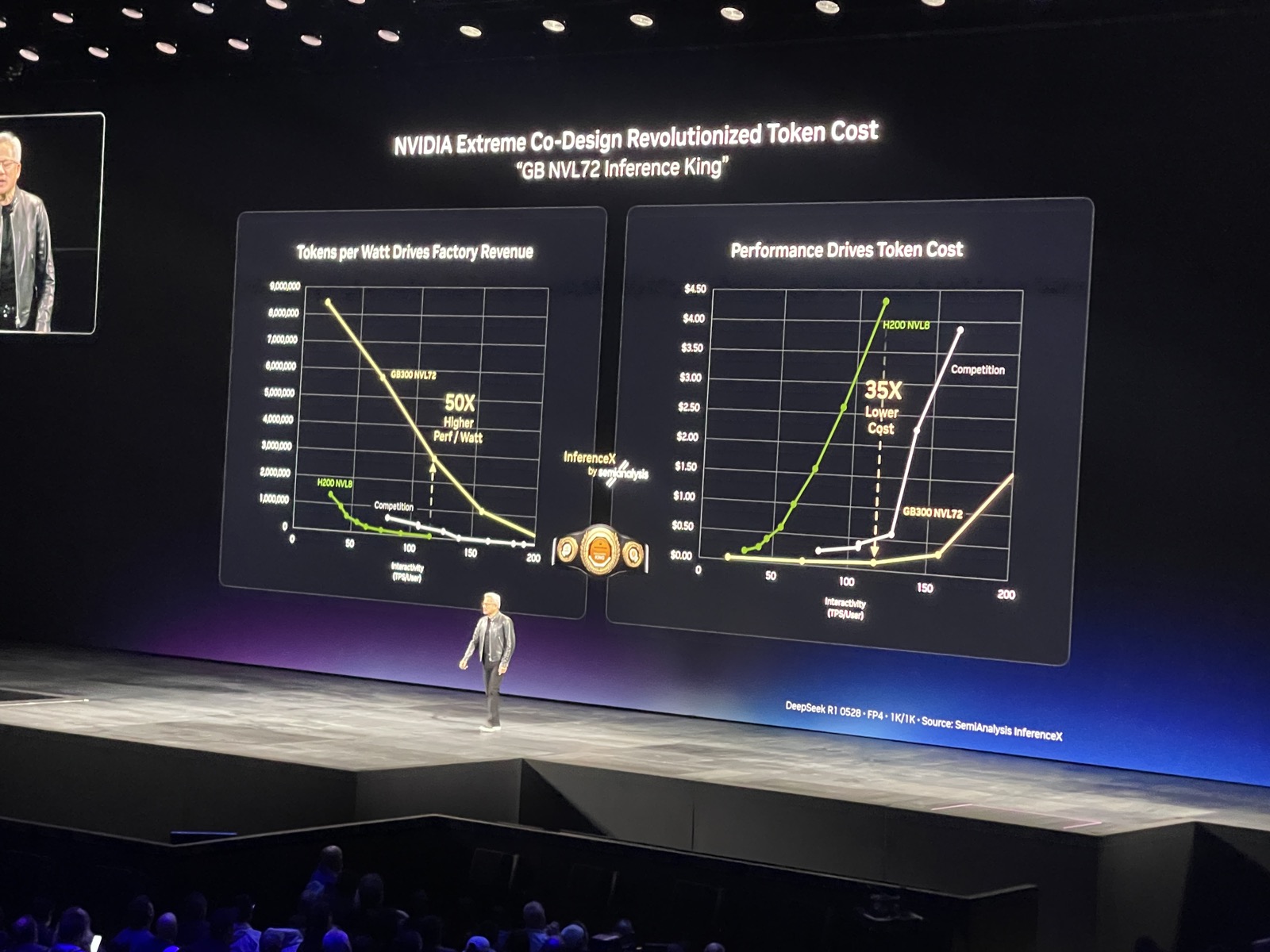
| NVIDIA Extreme Co-Design Revolutionized Token Cost · 3:57min |
Datacenters are constrained by a fixed amount of power (Watts) available. Emphasize Tokens Per Watt as the metric to maximize, and interactivity (token/s per User) as a use case differentiator. 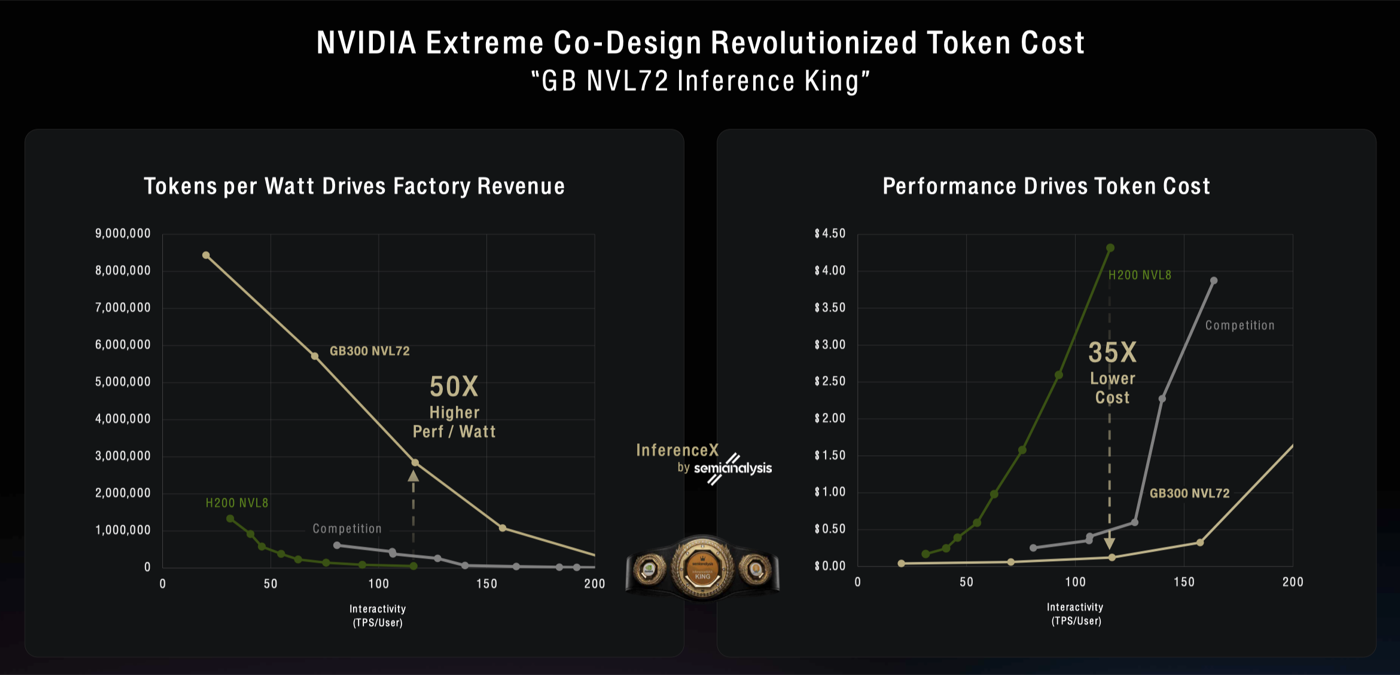 |
| InferenceMAX King · 1:23min |
| Shows how GB300NVL72 has improved on both efficiency and cost for inference and has been recognized by semianalysis as inference King! |
| NVIDIA is the Global Standard for AI Inference at Scale · 0:33min |
| Inference service providers should be seen as token factories. The output token rate from companies like eigen AI, together.ai, nebius, etc. has increased very fast, now reaching 400+ token/s for kimiK2.5 reasoning agent. Also see artificial analysis for a breakdown between providers. |
| AI Factories are the Industrial Infrastructure of the AI Era · 1:10min |
| Inference drives revenues and Token effectiveness is the most important metric. |
Full Vera Rubin hardware stack — GPU, NVLink, Rubin Ultra, and Spectrum-X Groq LPX + DSX platform for AI factory optimization (38min)
| A Decade of AI Infrastructure Innovation: From DGX-1 to Vera Rubin · 3:30min |
|
Jensen narrates NVIDIA's decade of data center infrastructure innovation:
2016
DGX-1 — packages 8 Pascal GPUs, first supercomputer built for deep learning, one delivered to OpenAI that year
2017
Volta — introduces NVLink 2 switch, GPU-to-GPU interconnect inside nodes
2019
Mellanox acquisition — allows the data center to become a single unit of computing
2020
Ampere / DGX A100 SuperPOD — brings scale-up via NVLink 3, scale-out via ConnectX-6 InfiniBand
2022
Hopper — supports FP8 Transformer Engine for Gen AI, NVLink 4, ConnectX-7
2024
Blackwell / NVL72 — achieves 130 TB/s bandwidth and a deeper rack-level co-design for top performance
2026
Vera Rubin — built for agentic AI · 35× throughput/MW · 40M× cumulative compute over the decade

|
| NVIDIA Vera Rubin · 2:27min |
| Jensen introduces the Vera Rubin hardware on stage |
| NVIDIA Vera Rubin, NVLink and Groq · 1:36min |
| He makes some interesting observations: with the recent tray designs, installation time falls down from 2 days to 2 hours. Also cooling is done with hot water at 45 degrees. |
| Spectrum-X Switch, Co-Packaged Optics, Vera and BlueField-4 · 2:09min |
| discusses the 8 grok 3rd gen tray which is in production and shows the Spectrum Co-packaged optics switch. Vera brings 2x performance per watt. ConnectX9 and storage platform are powered by Vera CPU. |
| Rubin Ultra · 2:03min |
| Jensen also shows VR Ultra and the new Kyber rack that can connect 144 gpus that now slide vertically into the rack. He also shows the new NVLink tray design that sits behind, also vertically. |
| Inference Performance and Efficiency Drive Company Results · 9:35min |
Jensen's main message to CEOs is how they will need to evaluate their company's usage of tokens, and study the tradeoff between throughput (as Token per Sec per MW) vs Interactivity (as token per second per user). Input and output Context length are growing and usage depends on use case. Jensen shows a graph partitionned by kind of model at different prices and how nvidia's chips performs on this tradeoff. The value of Ultra lays enabling bigger more interactive models with better energy efficiencies. GB NVL72 has increased the medium tier by 35x and Vera rubin will increase high tier by 3x and increased premium tier by 10x. Rubin + Groq LPX increase most valuable tier by 35x. Ultra enables even better interactivity. 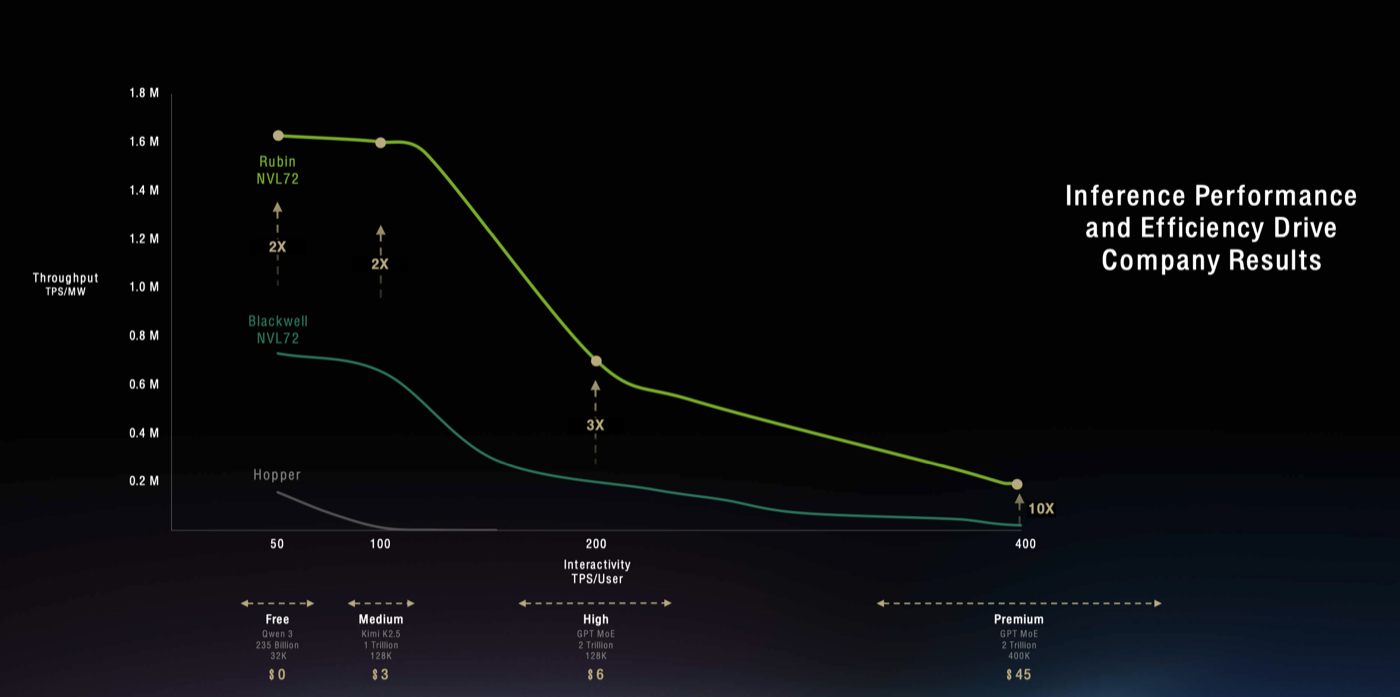 |
| Uniting Processors of Extreme Performances · 3:36min |
Jensen delves into the performance of Groq, which has high SRAM capacity (500MB) at very high throughput (150TB). This complements Rubin's 288GB of HBM4 memory at 22TB/s by providing statically compiled compute primitives specially used for the decode Feed Forward phase of AI inference, and helps achieve very low latency for token generation.  |
| NVIDIA Groq 3 LPX · 0:38min |
| Jensen shows Groq LPX manufactured by samsung and say he expects to ship by Q3 this year. |
| Announcing NVIDIA Launch Partners · 1:56min |
| shows all the AI labs, cloud, and OEM/ODM that will launch Vera Rubin. Expects production in the 1000s per week. also shows launch partners for Vera CPU and BlueField storage systems |
| NVIDIA Vera Rubin: 7 Chips – 5 Rack Systems · 1:02min |
Jensen shows how much progress was made by comparing x86 hopper generation to Vera Rubin GiGaWatt factory. VR can generate 350x more tokens per seconds than Hopper thanks to 35x more scale up BW per Rack (at 288TB/s) and with half as many GPUs.  |
| NVIDIA Extreme Co-Design Delivering X-Factors Every Year · 3:37min |
| shows the roadmap to 2028 with Feynman. Oberon will enable scale up in both copper and optical to support NVL576 racks (Kyber) and then NVL1152 for Feynman with Kyber. |
| NVIDIA DSX AI Factory Platform · 2:10min |
| Jensen describes the importance of the NVIDIA Omniverse solution to help design GW factory digital twins and reach max performance at lowest possible energy usage. He talks about tools for simulation such as DSX Sim, DSX exchange, DSX flex power management and DSX Max Q for dynamic power adjustment in the data center. |
| How AI Factories Maximize Tokens, Power, and Profit With NVIDIA DSX · 3:25min |
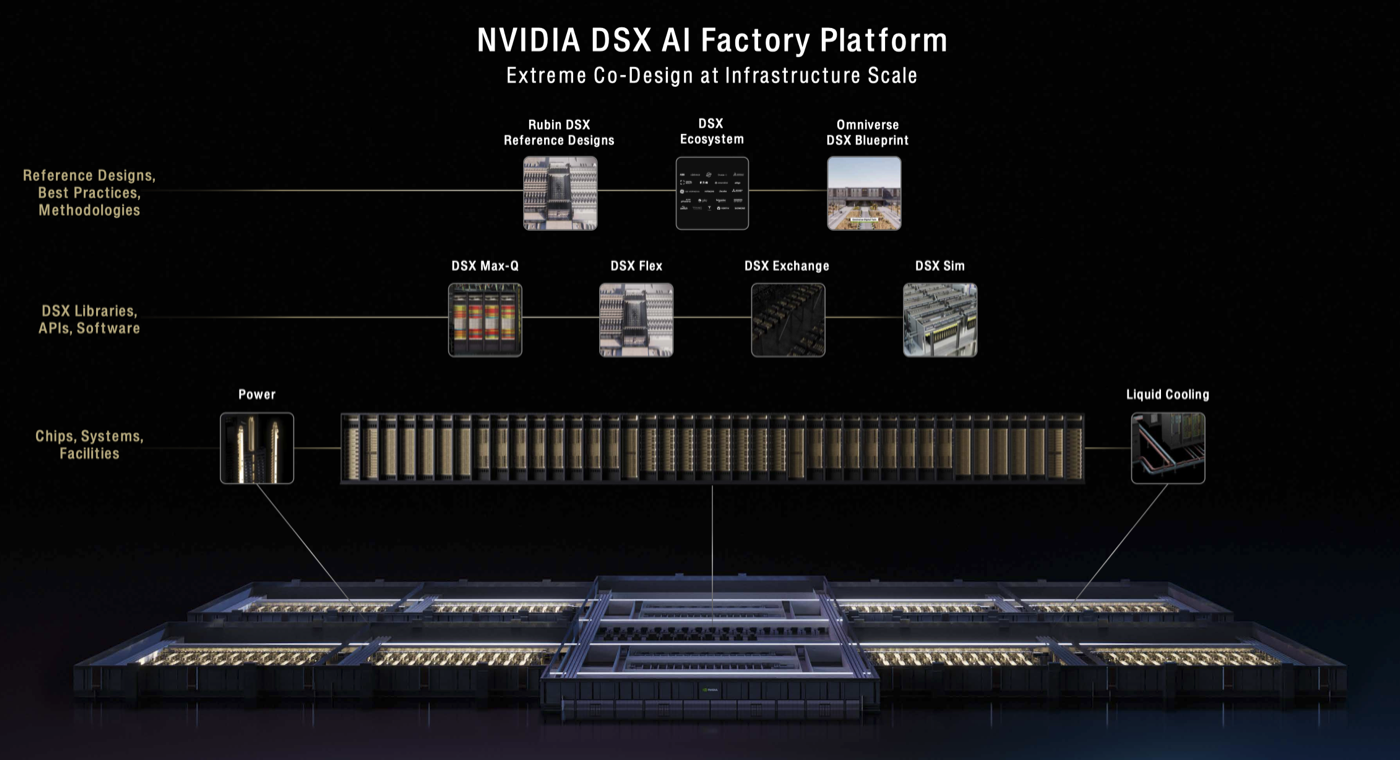 The video summarizes all the components of the DSX AI factory platform The video summarizes all the components of the DSX AI factory platform |
| Space-1 Vera Rubin Module · 0:43min |
| Jensen briefly mentions NVIDIA's foray in space with Space-1 Vera Rubin module and mentions the challenge of cooling in space. |
OpenClaw, NemoClaw, Open Model Coalition (19min)
| NemoClaw for OpenClaw · 1:24min |
Jensen is very excited about OpenClaw, the most popular open source in history, with the fastest project to get the most stars in github 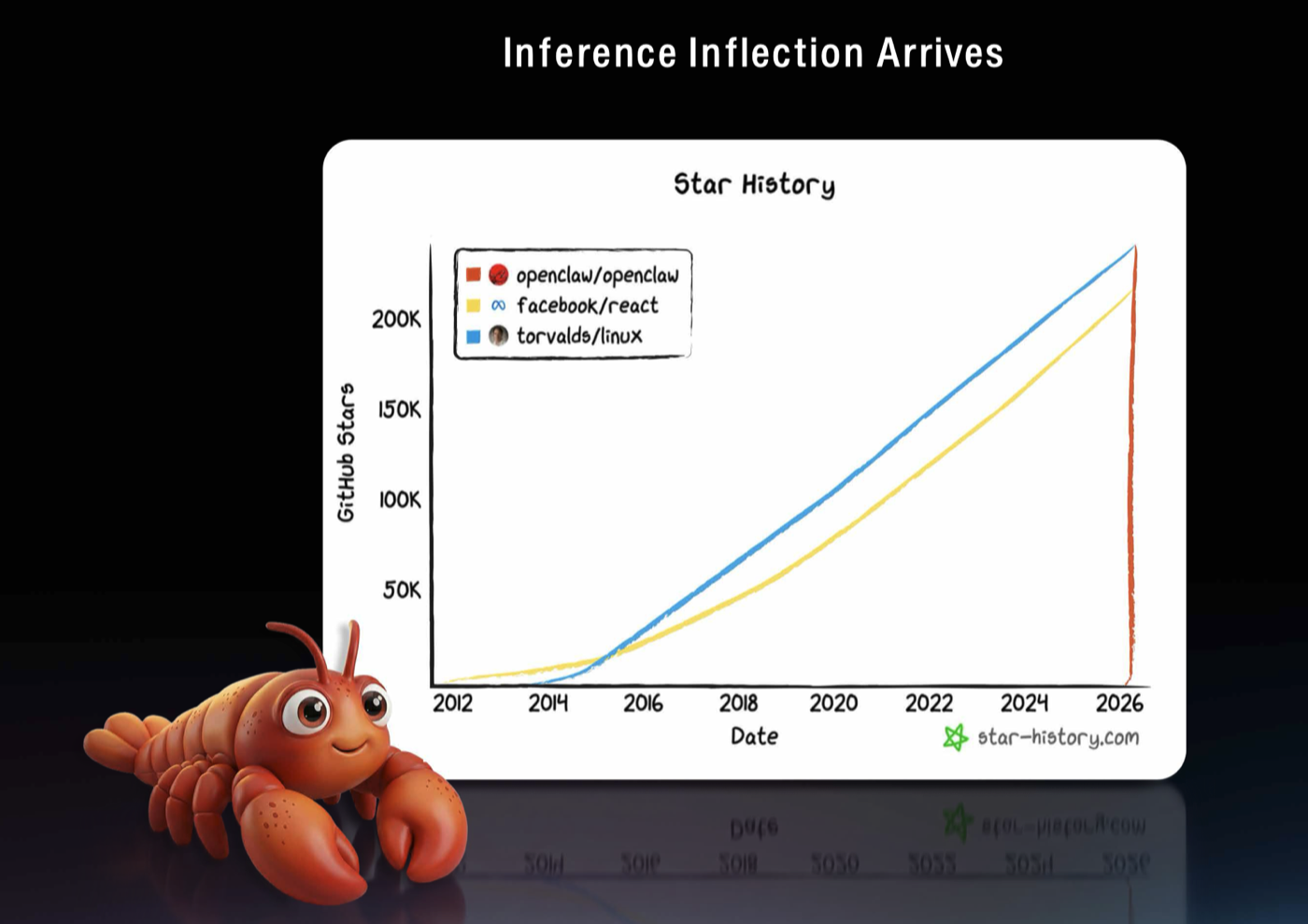 |
| OpenClaw: The ChatGPT Moment for Long-Running, Autonomous Agents · 9:14min |
| He shows how openclaw grew as a project to 340k stars on GitHub since the end of january 2026. It is the operating system of agents and every enterprise will soon need an OpenClaw strategy. |
| NVIDIA Nemotron and Open Models · 0:28min |
Jensen announces new models in Nvidia's open foundation model families: bioNemo for biomedical AI, earth-2 for Ai physics, Nemotron for Agentic AI, Cosmos for Physical AI, GROOT for Robotics, and Alpamayo for Autonomous Vehicles. 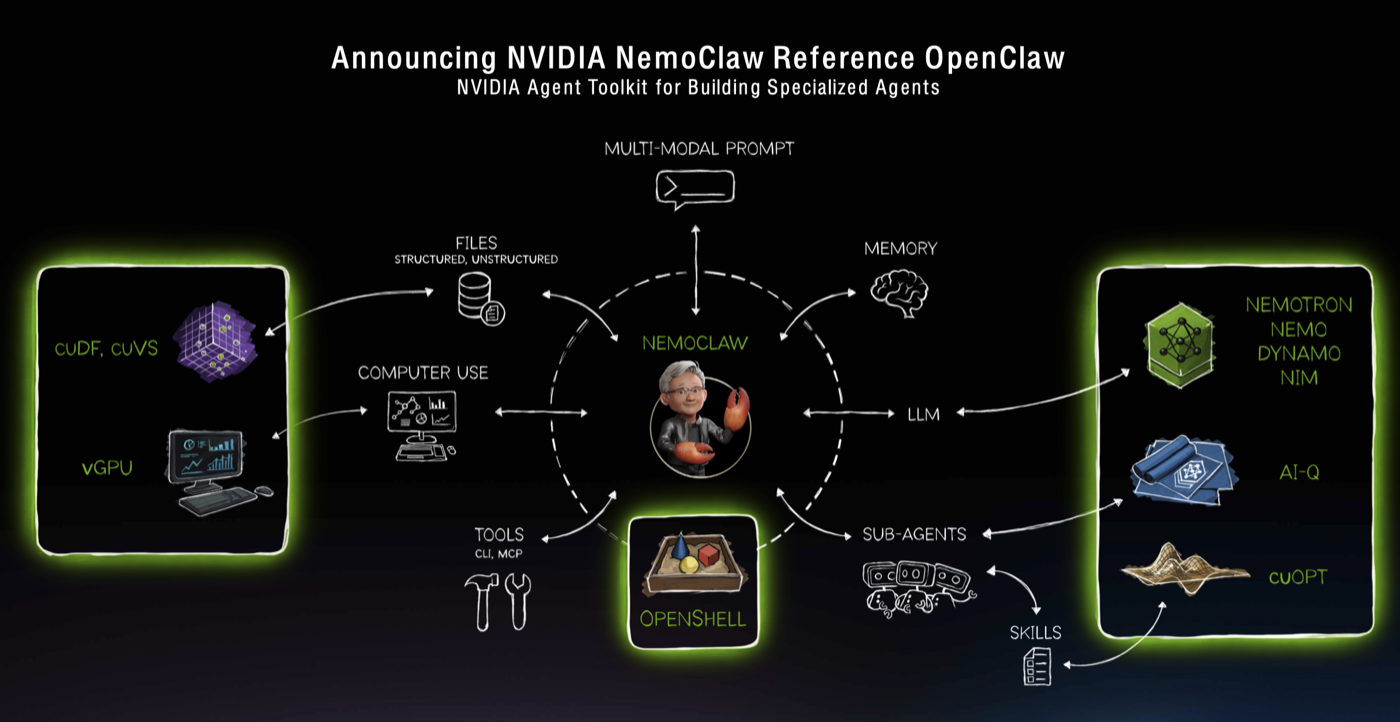 |
| How NVIDIA Open Models Power Every Industry's AI · 4:17min |
| The video shows models from each of the Nvidia families. They are world class, doing well on benchmarks. Shows nemotron-3-super-120b as #4 on best open model for openClaw. Nemotron 3 ultra. |
| Announcing Global AI Leaders Join NVIDIA Nemotron Coalition · 2:57min |
Jensen announces the NVIDIA Nemotron Coalition3 aimed at accelerating the co-development of open AI frontier models with partners Black Forest Labs, Cursor, LangChain, Mistral AI, Perplexity, Reflection AI, Sarvam and Thinking Machines Lab  |
| Announcing NVIDIA NemoClaw Reference OpenClaw · 0:39min |
| Jensen says the openClaw event cannot be understated and is as big as linux and html. In response, Nvidia is releasing NemoClaw, a reference enterprise-ready solution to secure openClaw deployments inside enterprises. |
Robotics, Physical AI, & recap (14min)
| Physical AI and Robotics · 3:11min |
| Jensen talks robots, mentions there are 110 robots at GTC, announces 4 new auto partners: BYD, Hyundai, Nissan, and Geely are joining Mercedes, Toyota, and GM to build robotaxi technologies. Jensen also announces a partnership with Uber to launch a large fleet of autonomous vehicles for 2027 on the NVIDIA DRIVE AV stack4 |
| The Age of Physical AI and Robotics · 4:27min |
This video shows how autonomous cars have been improving thanks to NVIDIA's and partner ecosystem.  |
| Olaf Takes the Stage With Jensen Huang · 1:55min |
| Jensen welcomes the only guest at the keynote. Last year it was a Star Wars inspired robot "blue", this year it is Olaf from Frozen |
| Official Keynote Closing Video · 4:02min |
| The Keynote ends with a generated video recapping the keynote with a jensen emoticon playing harmonica in the forest, surrounded by a band of robots playing instruments, a bit silly for my taste but again showcasing the power of the tools |
Full keynote is available here and the slides here.
References
- Semianalysis — Nvidia: The Inference Kingdom Expands — newsletter.semianalysis.com
- NVIDIA — Vera Rubin POD: Seven Chips, Five Rack-Scale Systems, One AI Supercomputer — developer.nvidia.com
- NVIDIA Launches Nemotron Coalition of Leading Global AI Labs to Advance Open Frontier Models — nvidianews.nvidia.com
- NVIDIA DRIVE Hyperion Achieves Level 4 Autonomy with Uber Partnership — nvidianews.nvidia.com