Accelerated Analytics for structured and unstructured data had a strong presence at this year’s GTC conference. First in the keynote, CEO Jensen Huang spent a good 20 minutes discussing how Enterprise AI offerings are powered by NVIDIA, with his “favorite” slides featuring NVIDIA’s RAPIDS libraries cuDF and cuVS sitting at the bottom of the whole software ecosystem for acceleration. See my post covering the full keynote for more.
Then there were many sessions covering these developments. In this post, I cover the four main technical ones.
-
Joshua Patterson and Todd Mostak open with a state-of-the-union on GPU-accelerated data processing where CPU analytics performance has stalled, how the NVIDIA ecosystem closes the gap, and what a next-generation analytics cluster looks like.
-
Greg Kimball and Zoltán Arnold Nagy then zoom into Presto specifically, walking through the concrete engineering required to turn GPU acceleration from theory into production reality at lakehouse scale.
-
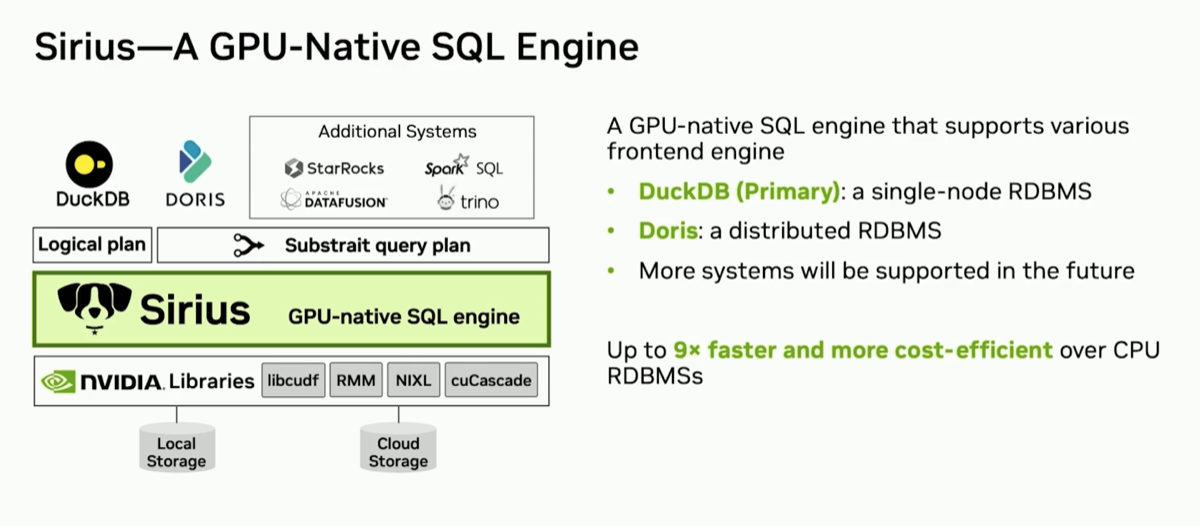
Bobbi Yogatama and Xiangyao Yu bring that story down to a single node, showing how their Sirius extension turns DuckDB into a record-breaking analytics engine without changing a single query.
-
Finally, Felipe and Rodrigo Aramburu go one layer deeper with cuCascade and a custom telemetry tool, the composable building blocks behind Sirius’s ability to handle datasets far larger than GPU memory.
This is Part 1 of my series on Accelerated Analytics at GTC 2026. Read Part 2: Industry Use Cases and Training Labs.
Technical Deep Dives
Joshua Patterson · VP, Solutions Architecture, NVIDIA
Todd Mostak · Sr. Director of Engineering, NVIDIA
NVIDIA Session overview
This session delivers a technical state of the union on GPU-accelerated data processing across SQL/DataFrames, vector search, ML, and decision optimization. Learn how GPU-native engines enable interactive analytics on massive lakehouse-scale datasets, real-time semantic and vector search over billions of embeddings, and makes the hardest ML and decision science workloads tractable, cost-efficient, and energy-efficient. The talk highlights the implications for high-impact scientific and enterprise computing, then looks ahead to what's in flight for 2026 and beyond, outlining concrete architectural patterns and practical guidance for building the next generation of GPU-accelerated data platforms and using them in your day-to-day work.
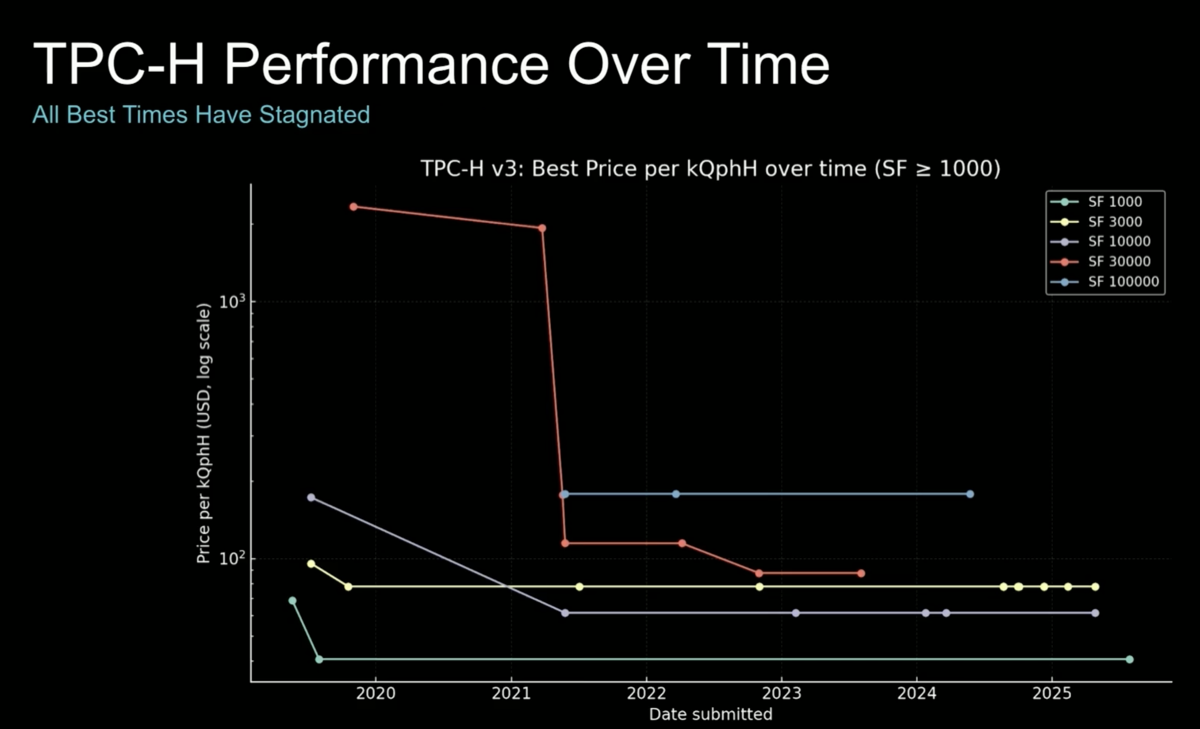
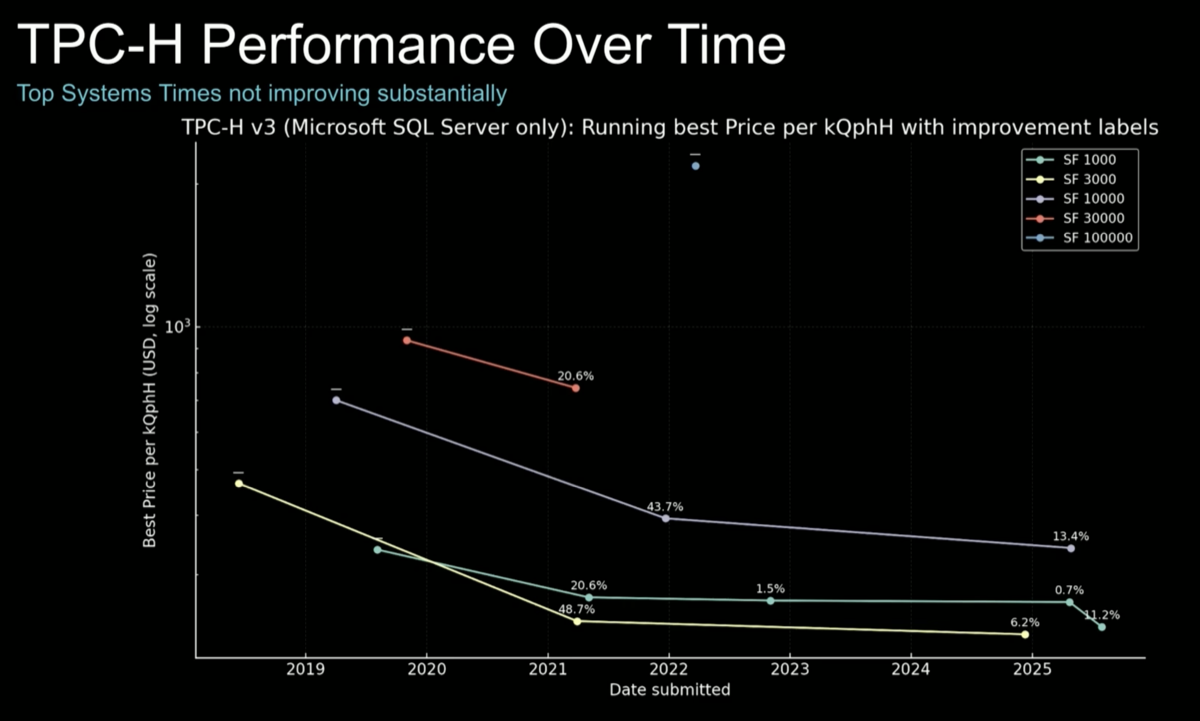
In this session, Joshua and Todd argue that CPU performance improvements on TPC-H have flattened over the past few years. They explore how the NVIDIA ecosystem can bring faster developments, either by adopting the new Vera CPU, migrating to cuDF/cuVS-accelerated databases, or redesigning data center clusters with analytics in mind to maximize the overlap of compute-intensive aggregations and joins vs IO-intensive tasks like shuffle and storage IO.
Takeaways
| 1. CPU TPC-H price/performance has flatlined |
@ 04:27 |
|
Speakers argue that over the past few years CPU performance for analytics has not improved by orders of magnitude. For example, SQL Server and peers show only 15–20% gains every two years, probably just due to CPU refresh cycles. They also argue NVIDIA can help push the field forward.
|
| 2. Vera CPU accelerates analytics for free |
@ 05:17 |
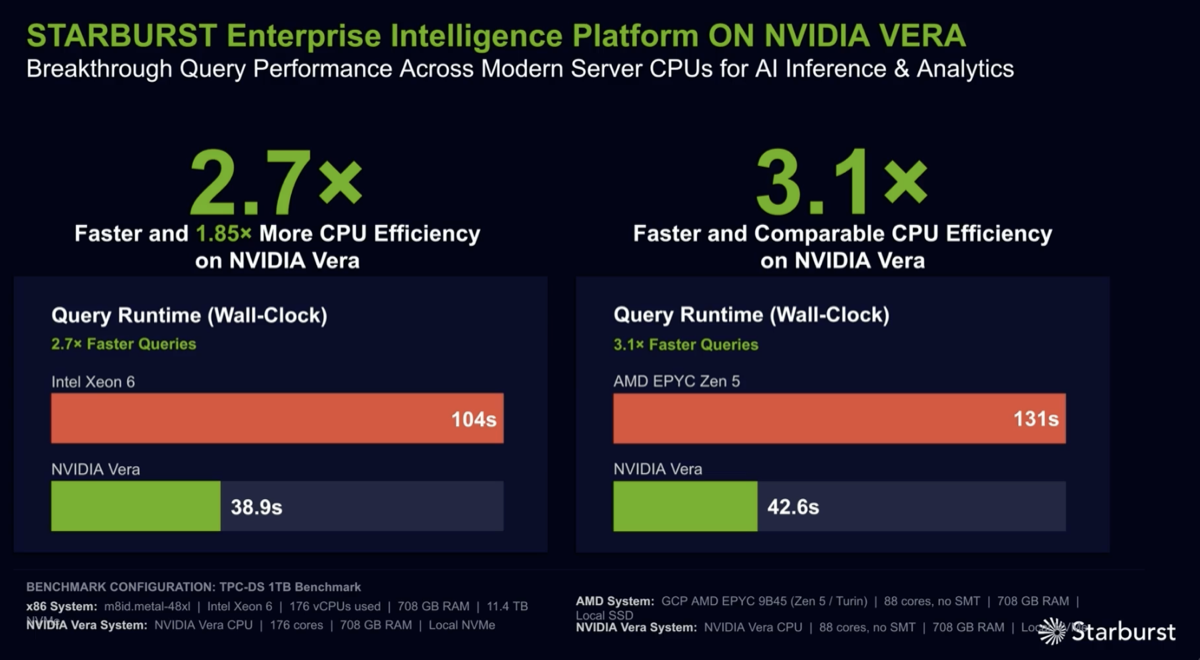
Vera CPU shows impressive performance improvements for analytics workloads. Some of the attributes that make it a good fit are: 1) massive amount of memory BW (1.2 TB/s) 2) "tons of cross-section BW that avoids the NUMA locality problem seen in multi-socket machines" 3) lots of BW/per core (14 GB/s per core, 3× that of x86/ARM)
➜ Vera gives analytics workloads a 2.5–3× lift with zero recompilation. Starburst, Kinetica, Redpanda all validate this. More GPU headroom per watt is the secondary win. Speakers show the performance on the TPC-DS Benchmark with Vera CPU compared to Intel and AMD for the Starburst Lakehouse, which is built on Trino.
|
| 3. Enterprise unstructured data: cuVS helps close the indexing gap |
@ 08:54 |
|
90% of enterprise data is unstructured but only 10% is properly indexed. GPU-accelerated CAGRA (a graph nearest neighbor algorithm that outcompetes the CPU based HNSW) hits 10–13× faster indexing vs CPU HNSW at equivalent accuracy, on a cheaper instance. CuVS Plugin integration with Milvus, Elasticsearch, and OpenSearch means no rewrite required.
|
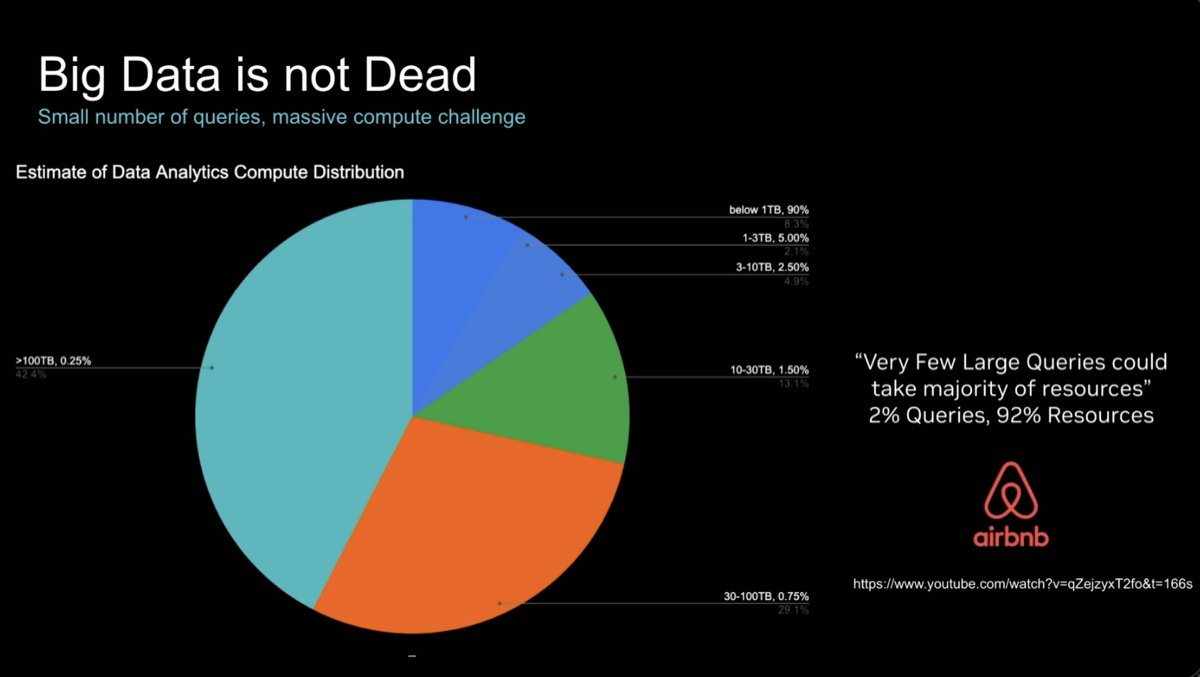
| 4. 2% of queries consume 92% of cluster resources. |
@ 11:15 |
|
An interesting statistic from Trino usage at Airbnb shows that 2% of queries consume 92% of cluster resources. cuDF was created to help with this, first as a simple pandas drop-in replacement, but now more targeted at accelerating large-scale systems like databases and lakehouses such as Spark, Trino, Presto, and DuckDB. Companion libraries support efficient memory management, filesystem transfer, distributed communication, data prefetching, etc.
|
| 5. Sirius on DuckDB on a single GB300: 21 seconds for TPC-H 1 TB |
@ 19:01 |
The speakers reference a later session on SiriusDB showcasing how fast the acceleration is. The Sirius cuDF-DuckDB integration delivers 7× TCO on ClickBench. Transwarp's TPC-DS 150 GB run clocked 26× faster than CPU DuckDB on the same GPU.
Another accelerated database mentioned (@19:45) is Heavy AI / OmniSci, which will be open-sourced in late Q2 2026. It features LLVM compilation engine, Vulkan in-process rendering, geospatial/time series support, fast OLAP. Todd Mostak is now at NVIDIA leading this.
|
| 6. Theseus's async mini-executor architecture + GPU Direct Storage help break the memory wall |
@ 20:41 |
The Theseus engine from Voltron was able to run TPCH-100TB on 2 DGX A100 servers (each with 8× A100 80GB/GPU, 640GB total GPU HBM2e memory, 2TB/s per-GPU memory bandwidth, connected via NVLink 3.0 at 600GB/s) + 200 Gbps InfiniBand + GPU Direct Storage. GDS enables all GPUs to talk directly to storage network instead of waiting for data to be served via a single CPU attached to the system. The practical consequence: petabytes of NVMe storage becomes queryable working memory. Replacing the monolithic executor with specialized actors — compute, memory-tier management, prefetch/decode, networking — enabled true overlap of I/O and compute. The speakers described it as "an agent swarm for query processing." See the Theseus paper for more on the architecture.
|
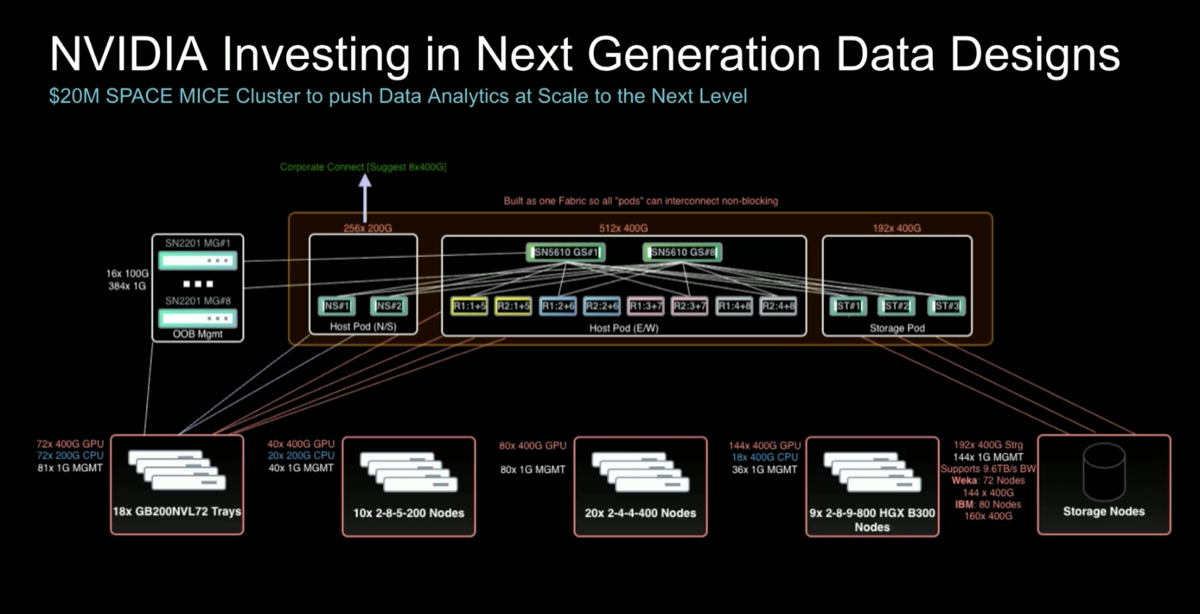
| 7. SPACE MICE: a reference design to push data analytics clusters to the next level |
@ 24:53 |
|
This design consists of 1) 1 GB200 NVL72 2) 9 DGX B300 3) 10 RTX PRO 6000 nodes 4) 20 RTX 4500. NVLink is mainly for all GPU-to-GPU shuffle (east-west, ~1.8 TB/s) while CX8 NICs are dedicated to storage I/O (north-south, 3–4 TB/s). The two networks run simultaneously and non-overlapping. 18 GPUs × 100 TB reachable per TB of GPU memory = ~1.8 PB per rack. Vera Rubin (144 GPUs) pushes this to ~5 PB.
|
The next session zooms in on one of the distributed engines in that ecosystem — Presto — and walks through the concrete engineering work required to make GPU acceleration practical at scale.
Greg Kimball · Software Engineering Manager, NVIDIA
Zoltán Arnold Nagy · Sr. Software Engineer, IBM Research

NVIDIA Session overview
Running interactive SQL at scale is still far slower, and more expensive, than it should be. This session explores how GPU acceleration fundamentally changes that equation. We'll dive into open-source community work speeding up the popular open data lakehouse engine Presto—work that required rethinking not just the core execution engine, but also the surrounding system components that drive performance at scale. We'll walk through benchmark results, lessons from real enterprise deployments, and the architectural details that actually matter in practice. You'll leave with concrete guidance for GPU-accelerating your own data processing workloads to achieve better performance at lower cost.
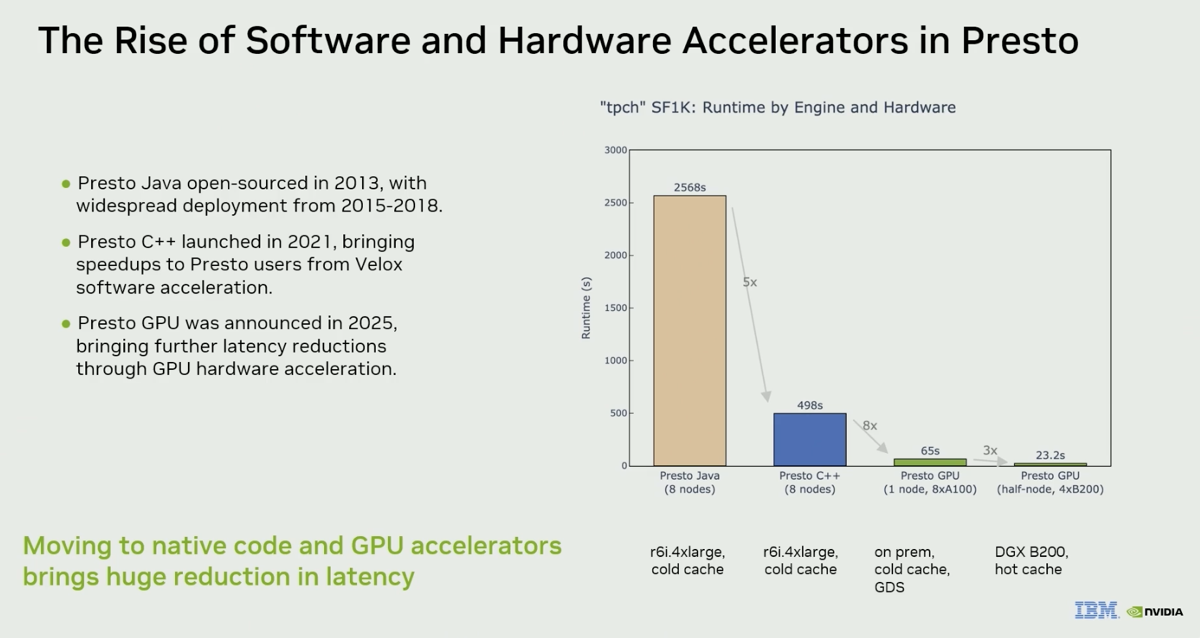
This session focuses on the distributed SQL engine Presto and recent performance improvement for its GPU accelerated mode. It is presented by Greg from NVIDIA’s cuDF team, and Zoltan from IBM Research and working on Presto. Presto C++ workers use the open source project Velox as single node query engine and Velox provides experimental support for GPUs via the RAPIDS AI libraries including cuDF. See this article from last year on Velox over cuDF. The picture below shows the evolution of the Presto project from native Java to Native C++. Together with Spark, Presto is one of the most stable and widely adopted open source systems for distributed data processing.
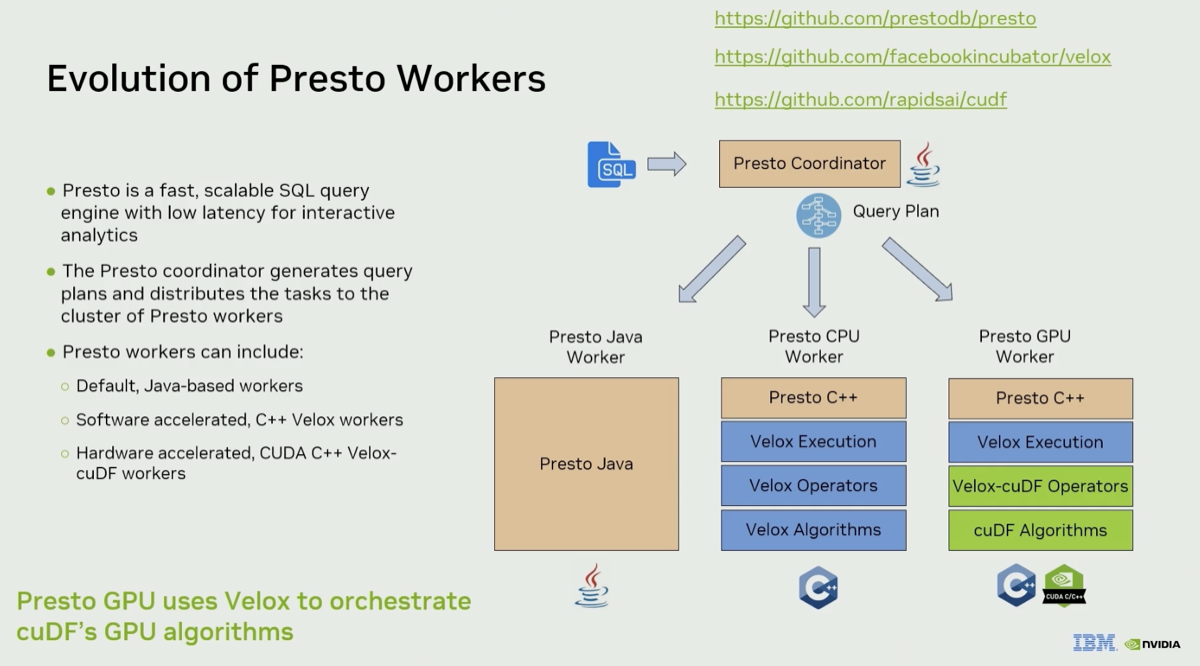
Takeaways
| 1. Presto GPU node is 30× faster than an 8-node Grace CPU cluster on TPC-H SF1K |
@ 05:29 |
|
The comparison baseline is "each node has a two socket Grace CPU" running the 22-query TPC-H-derived suite. Four B200 GPUs drop that to "30 times faster speed" — supports caching ingested Parquet data. Powered by Velox and cuDF under the hood.
|
| 2. Table scan & Parquet I/O dominates TPC-H runtime — not compute |
@ 07:22 |
The operator breakdown at SF-100 and SF-1K shows the "big blue part, parquet data source" dwarfs hash join, filter, and partitioning combined and accounts for 60-70% of the runtime. Tuning Presto GPU is almost entirely an I/O problem.
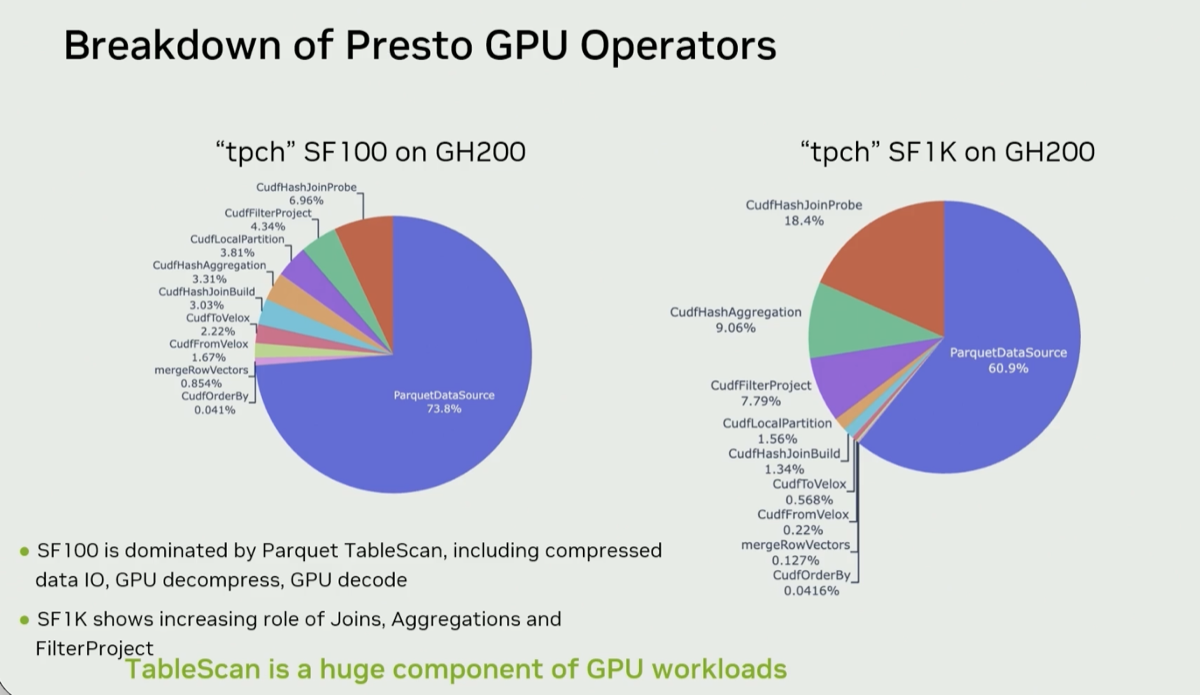
|
| 3. Picking a good file format encoding + using NUMA pinning improves performance by ~30% |
@ 08:29 |
"The Delta binary packed encoding came out with Parquet… it makes a huge difference on GPU execution." For integer physical types, switching to DBP encoding is described as a way to make your data lake "scream fast on GPU." Also, NUMA pinning on DGX boxes gives a significant GPU speedup. On a DGX, one CPU is connected close to four of the GPUs. Keeping that CPU in charge of all CUDA launching and copy activity for its four GPUs improves throughput.
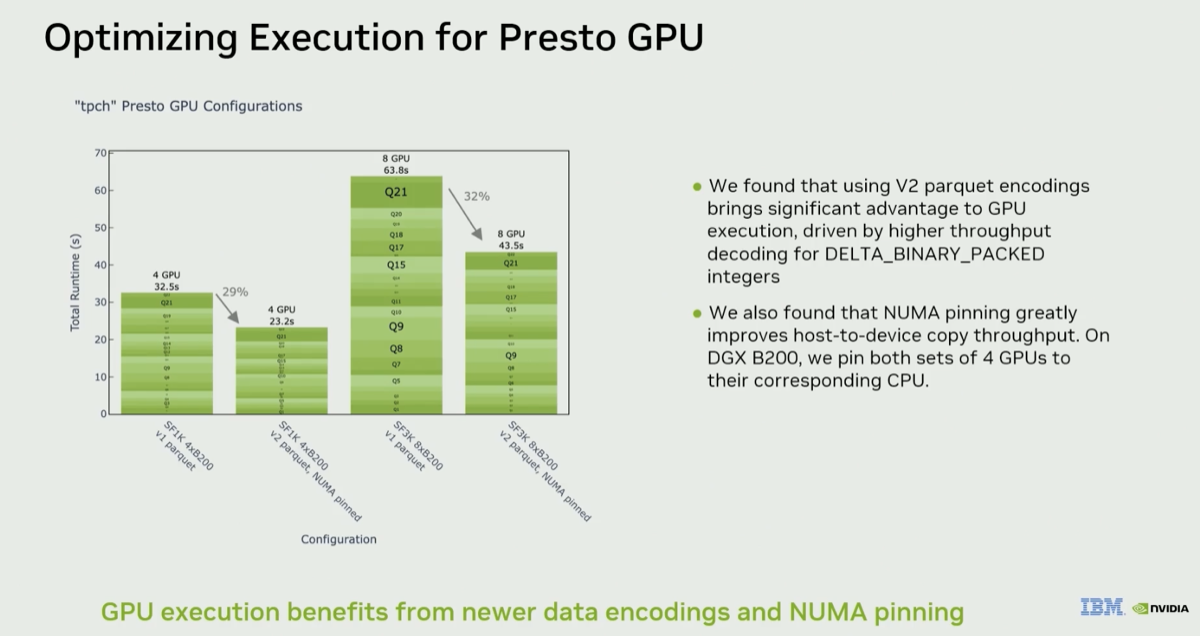
|
| 4. 10x lower TCO for Presto GPU when running all TPC-H queries |
@ 09:33 |
Greg's cost-per-run chart shows that for SF1K (1TB), a single GPU delivers better price/performance than four. At SF3K (3TB), three GPUs beat eight. The headline: "around a 10x benefit using Presto GPU versus Presto CPU" — but only if you optimize for cost, not raw speed. Perhaps counterintuitively, the $ cost per performance is more pronounced for smaller cluster with less capable hardware, "that's where the TCO story is" says Greg.
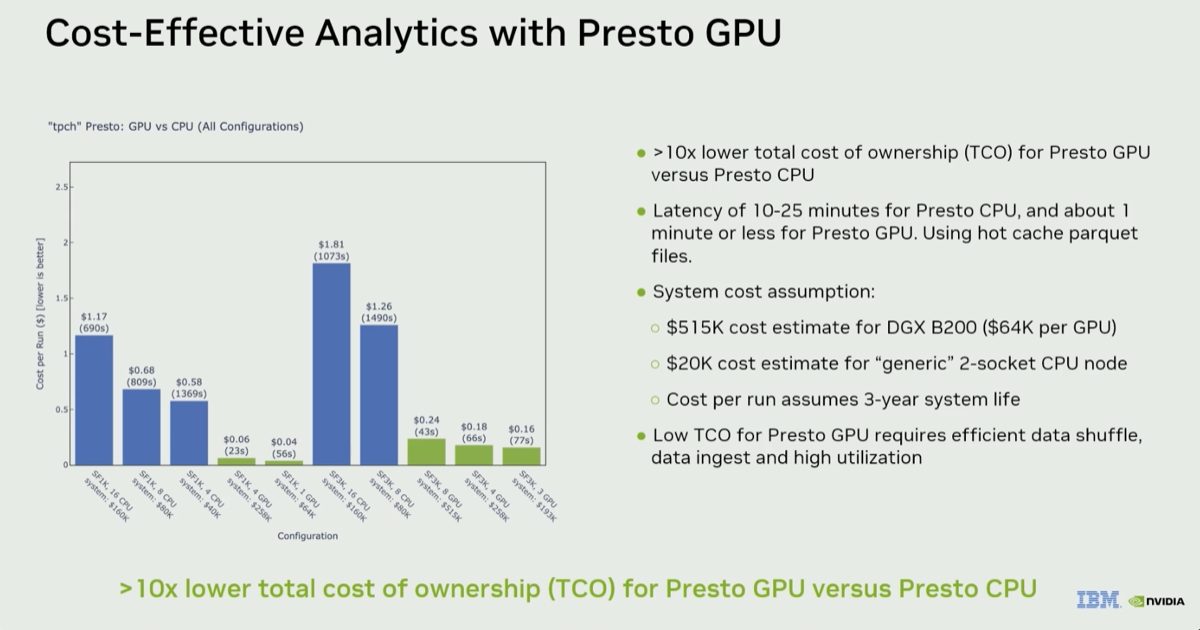
|
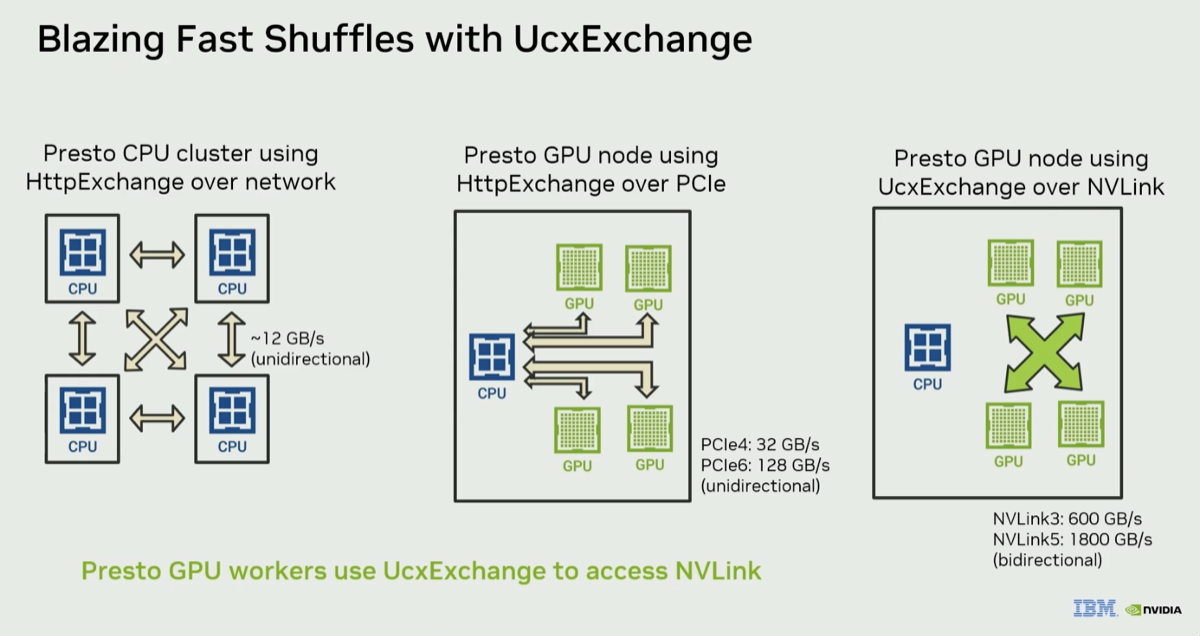
| 5. UCX exchange operator enables 900 GB/s NVLink5 for data shuffle |
@ 13:22 |
|
Zoltan's comparison: normal Linux kernel TCP "just doesn't have the bandwidth" once you go multi-hundred gigabit. NVLink 5 on Blackwell delivers "1800 gigabytes a second bi-directional bandwidth" — "900 gigabytes a second to move between GPU to GPU." Presto uses UCXExchange to select NVLink when available and falls back gracefully to RoCE or TCP otherwise. It's a drop-in replacement. Zoltan shows a TPC-H SF1K benchmark comparison between 16x Grace CPU (8 nodes), 8xA100 with Http exchange and 8xA100 with CuDFExchange and shows the dramatic drop from 690s ➜ 453s ➜ 60s!
|
| 6. S3 on cloud has a *per-VM* BW ceiling AWS doesn't officially document |
@ 19:18 |
AWS will throttle traffic from a single VM. The workaround is to spin up CPU instances that pull from S3 in parallel and write directly to GPU memory bypassing host memory entirely. On B300, "AWS gives you 800 gigabit per GPU (100GB/s), and it has eight GPUs, 6.4 terabits a second of bandwidth (800GB/s) to fill up", performance you would never be able to achieve on a single S3 connection.
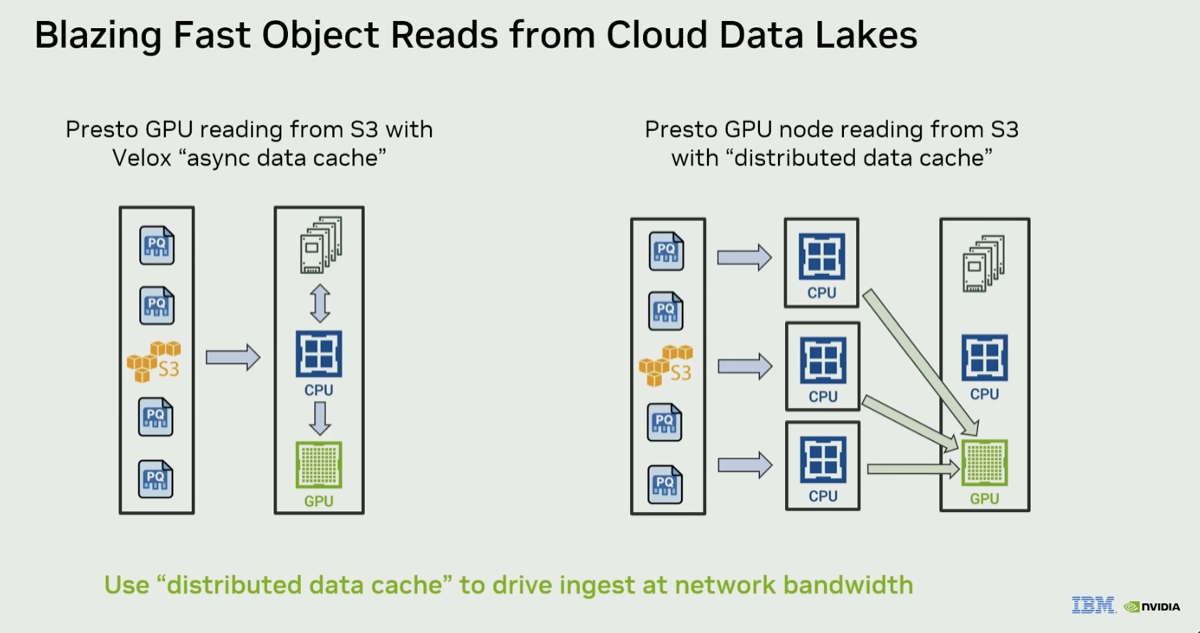
|
| 7. Velox "Async data Cache" improvements drop the runtime further for hot queries |
@ 24:29 |
By reading Parquet metadata first to predict what will be fetched, nearby small reads are combined into larger requests: "just coalescing the reads drops your request number from 700 to around 200." Parallelism is preserved but metadata overhead drops, pushing the hot run to ~20 seconds — described as "basically saturating the PCI Express bus on the RTX 6000."
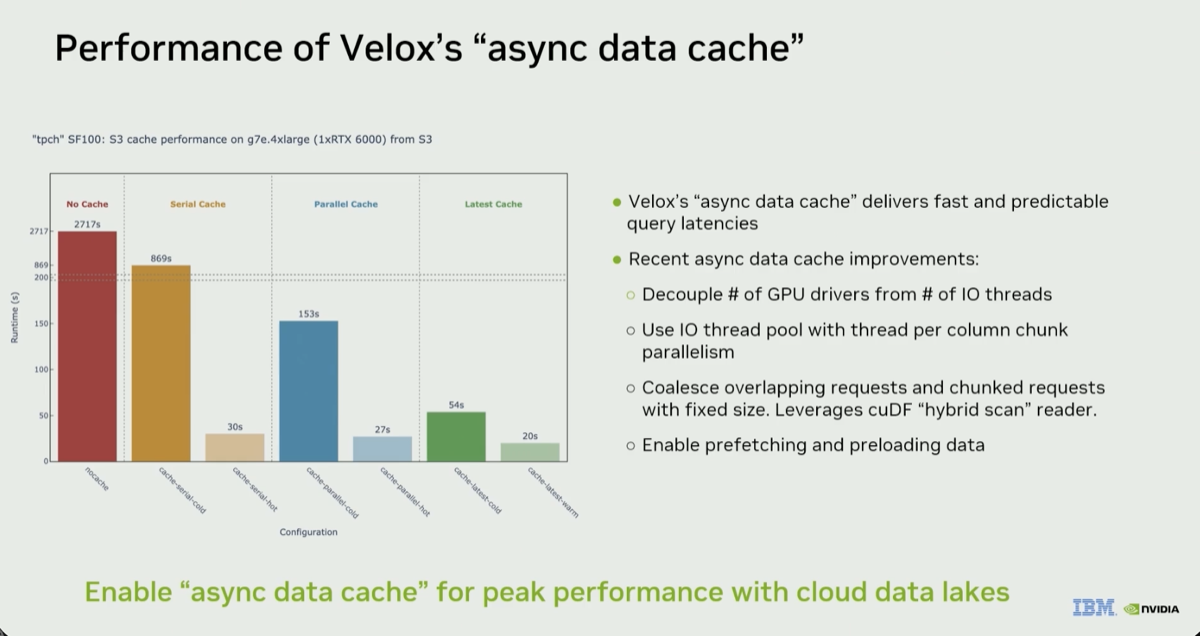
|
| 8. UDF needs more support in libcuDF + overlapping shuffle with Parquet |
@ 34:30 |
|
JIT compilation for supporting User defined functions in libcudf will be a big part of the story needed to bridge the gap to wider adoption in the industry. Also supporting parallel IO traffic from different sources such as for shuffle and table scan was a big challenge. A recent article digs into the latest JIT improvements in cuDF for string transform UDFs Efficient Transforms in cuDF Using JIT Compilation
|
From distributed clusters to single-node: the next session covers Sirius, the GPU extension that turns DuckDB into a record-breaking analytics engine.
Bobbi Yogatama · Sr. Systems Software Engineer, NVIDIA
Xiangyao Yu · Assistant Professor, University of Wisconsin-Madison

NVIDIA Session overview
DuckDB has become the analytical engine of choice everywhere—from notebooks and embedded applications to production data workflows. At the same time GPUs have rapidly evolved into powerful and cost-efficient engines for general-purpose parallel compute. Sirius brings these two trends together by enabling GPU-native execution for DuckDB—without requiring users to change how they write queries. In this session, we'll explore how Sirius offloads DuckDB workloads to GPUs, accelerating analytics by up to 8x at the same hardware rental cost. Learn how this new architecture combines DuckDB's simplicity with the power of GPU compute, unlocking faster, more cost-efficient interactive analytics while preserving the elegance of a single-node engine.
GPU is becoming a general purpose computing system. OLAP data systems stand to benefit because there are lots of parallelizable algorithms in analytics. Recent SW/HW trends are helping overcome traditional challenges to GPU accelerated databases like GPU memory, CPU-GPU PCIe bottleneck, and engineering complexity. Sirius uses DuckDB’s modularity to bring GPU acceleration without requiring any changes to end-user queries. More in the recent article NVIDIA CUDA-X Powers the New Sirius GPU Engine for DuckDB, Setting ClickBench Records
Takeaways
| 1. ClickBench world record: Sirius holds #1 and #2 on hot run at $2/hr |
@ 06:37 |
Sirius took both first and second place on the ClickBench hot-run leaderboard — GH200 on LambdaLabs and H100 on AWS — and holds first on the combined run. The GH200 instance costs $2/hr, far below the CPU-based systems it beats. When you normalize for cost, the gap widens even further.

|
| 2. GPU-only execution: fall back to DuckDB entirely, never hybrid |
@ 07:53 |
|
Sirius does not mix CPU and GPU execution within a single query. When it encounters an unsupported operator, it falls back cleanly to stock DuckDB — "the worst performance that you can get is a DuckDB performance, which is pretty damn good." This avoids the complexity and performance cliffs of hybrid scheduling while preserving correctness. It's interesting that the direction of newer systems seems to be GPU or CPU only rather than hybrid CPU-GPU execution which has been a topic of research in the past few years from the speaker's own work with Mordred as well as other projects like CoGaDB, Ocelot, and HetExchange. See Yogatama's phD thesis for more details, including Sirius.
|
| 3. Live demo: TPC-H Q9 on 1TB Parquet — 2.5s vs 16s, data exceeds GPU memory |
@ 10:30 |
|
On a GB300 DGX station, Sirius completes TPC-H Query 9 against a 1 TB Parquet dataset in 2.5 seconds; DuckDB on CPU takes 16 seconds. The data intentionally exceeds GPU memory — cuCascade spills transparently to host. Results between the two engines are identical. The CPU instance was c8id.metal-96xl which contains a 384 cores Intel Xeon CPU with 768GiB memory.
|
| 4. DuckDB creator announces Sirius as the official GPU extension |
@ 12:03 |
Hannes Mühleisen, creator of DuckDB, appeared on stage to announce that Sirius will become a core DuckDB extension — "the blessed way of running queries on GPUs with DuckDB." This signals GPU-accelerated execution moving from an external experiment to an officially endorsed path in the DuckDB ecosystem.

|
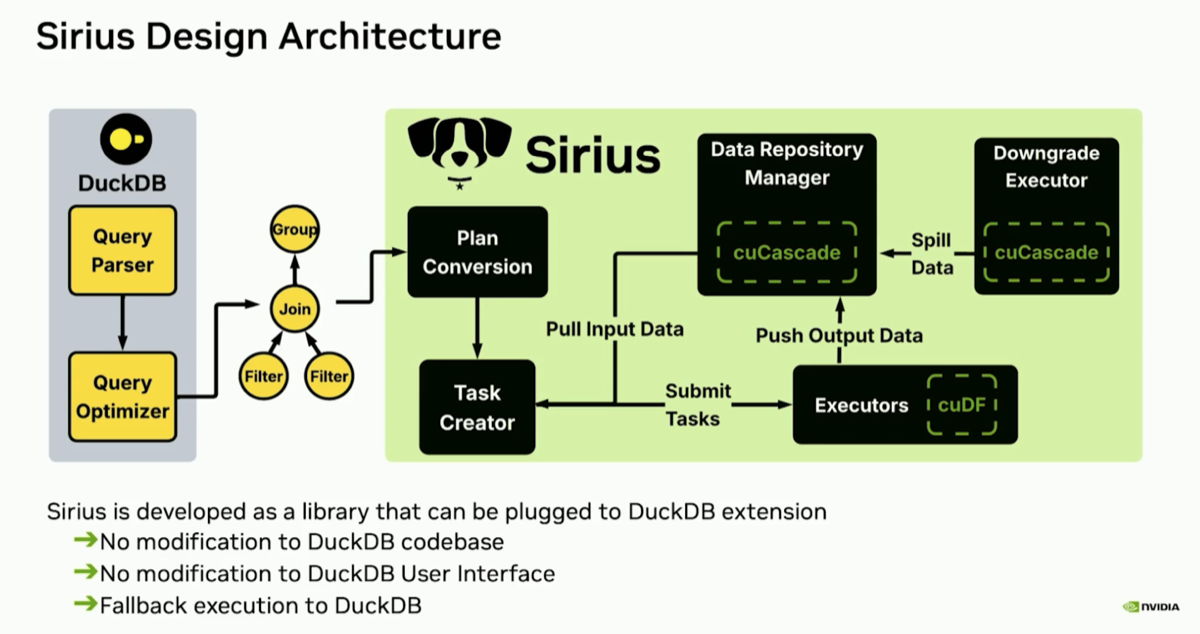
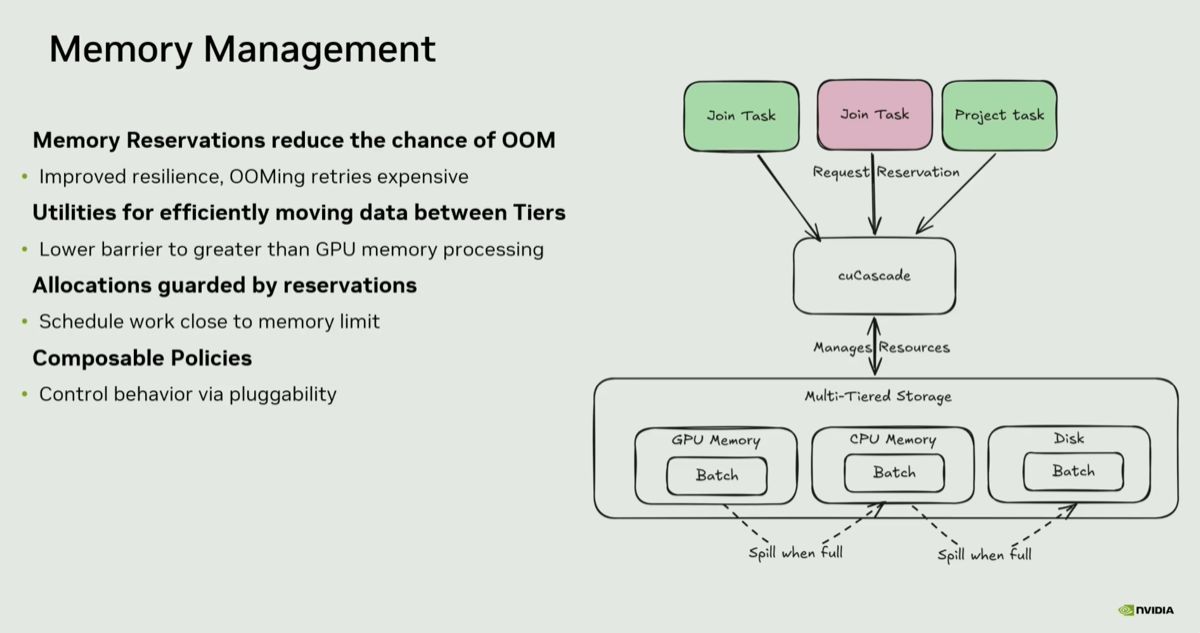
| 5. Sirius implements separate executors for compute and spilling |
@ 24:43 |
|
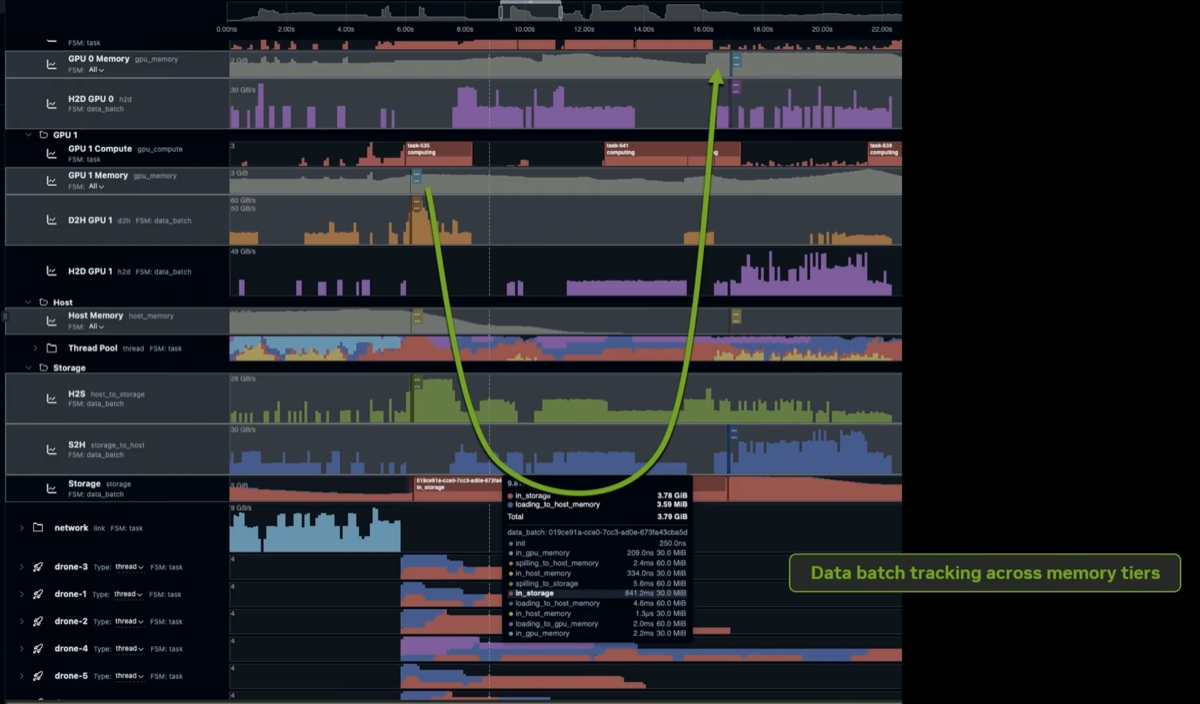
In Sirius a collection of Data Batches are managed by a Data Repository Manager that relies on cuCascade and a downgrader executor to manage spilling either back to the CPU host memory or to the GPU. Data spilling can happen simultaneously with the data processing on other data in the GPU. New operators are added in the plan to support spilling from GPUs.
|
| 6. Sirius achieves 5x speed for DuckDB on TPC-H queries using 1 DGX GB300 |
@ 24:43 |
Running the full TPC-H SF1K (1 TB) suite on a DGX GB300 node, Sirius completes all 22 queries in 21 seconds total — a 5× speedup over DuckDB. The presenter notes: "the TPC-H official record is actually slower than 21 seconds," implying this result, while informal, would be the fastest ever recorded at this scale factor. Compare with Presto performance shown in previous session which got 24s on a 1/2 DGX B200 node (using only 4x B200)
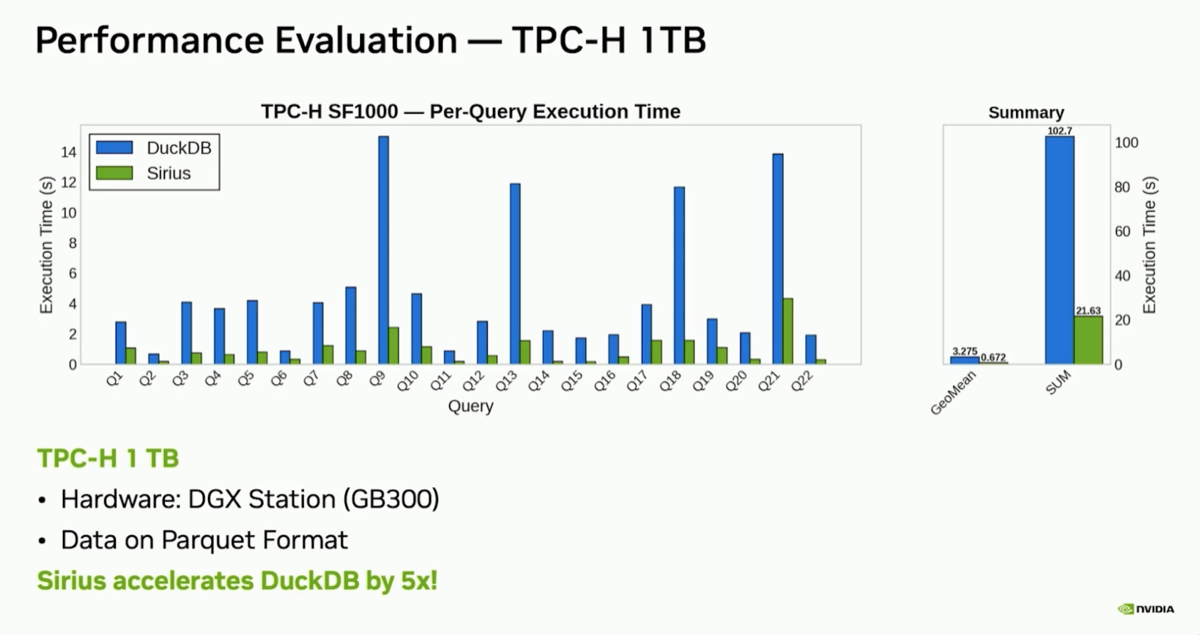
|
| 7. 9× TCO at the same $2/hr cost: GH200 Lambda Lab vs AWS CPU instance |
@ 25:53 |
On the SF300 hot-run benchmark, Sirius on a GH200 (2022 Grace-Hopper on LambdaLabs, $2/hr) delivers 9× better TCO than DuckDB running on a comparably priced AWS Intel CPU instance (r8i.8xlarge). Same dollar spend, same wallclock budget — 9× the throughput. The implication: GPU instances are no longer a premium option; at equivalent cost they dominate.
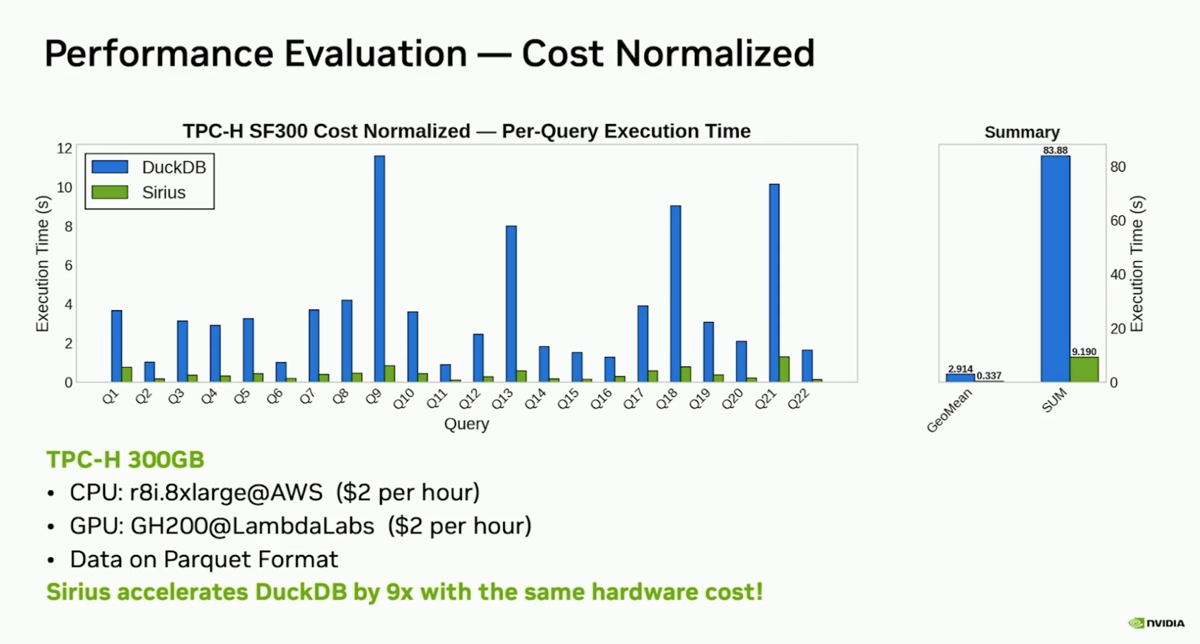
|
| 8. Sirius manages its own pinned memory cache — 2× transfer speedup on GB300 |
@ 32:43 |
|
Rather than relying on the OS page cache, Sirius maintains its own pinned memory buffer. This allows it to transfer data from host in compressed form and decompress on the GPU, bypassing the pageable memory path entirely. On GB300, this yields up to 2× higher sustained transfer throughput — a gain that disappears if you let the OS manage the cache.
|
Sirius’s spilling story depends on a library that wasn’t widely known until this conference. The final session pulls back the curtain on cuCascade and the telemetry tooling built alongside it.
Felipe Aramburu · Distinguished Solutions Architect, NVIDIA
Rodrigo Aramburu · Developer Relations for Data Processing, NVIDIA
NVIDIA Session overview
As GPU-accelerated analytics scale to terabytes and beyond, memory management and observability become critical infrastructure. We introduce a composable, engine-agnostic approach to shattering GPU memory limits and understanding query-level resource consumption. We'll deep-dive into cuCascade, a library for memory reservation and topology discovery that prevents out-of-memory failures by gracefully spilling data between GPU, host, and disk memory tiers. We'll also introduce a semantic telemetry layer for always-on profiling, enabling developers to visualize query plans and resource throughput across GPUs in real time. We demonstrate both tools working together inside Sirius, NVIDIA's GPU-native analytics engine, showing real telemetry output and memory tier management on live workloads. Learn how these composable building blocks help engine developers identify bandwidth bottlenecks, optimize memory utilization, and push toward speed-of-light analytics performance.
This talk is all about piercing through the GPU memory wall and the experience Felipe and Rodrigo had working on this problem from BlazingSQL to Theseus engine and now at Nvidia. They believe that GPU memory capacity is no longer as big of a problem, rather it is data movement that is now the real cost and the primary challenge. They also emphasize memory frugality as the idea of using more compute if it leads to fewer memory accesses.
Takeaways
| 1. GPU main challenges: *memory movement* + *memory frugality* |
@ 01:44 |
The session opens with introducing the memory wall challenge and conceptually inversion of the CPU paradigm. On CPU, you minimize compute to save memory bandwidth. On GPU, the argument is the opposite: "pay a higher computational cost because there is leftover compute inside the GPU to shrink the amount of bytes for the amount of time that you necessarily have them in memory." Memory is the scarce resource; compute is not.
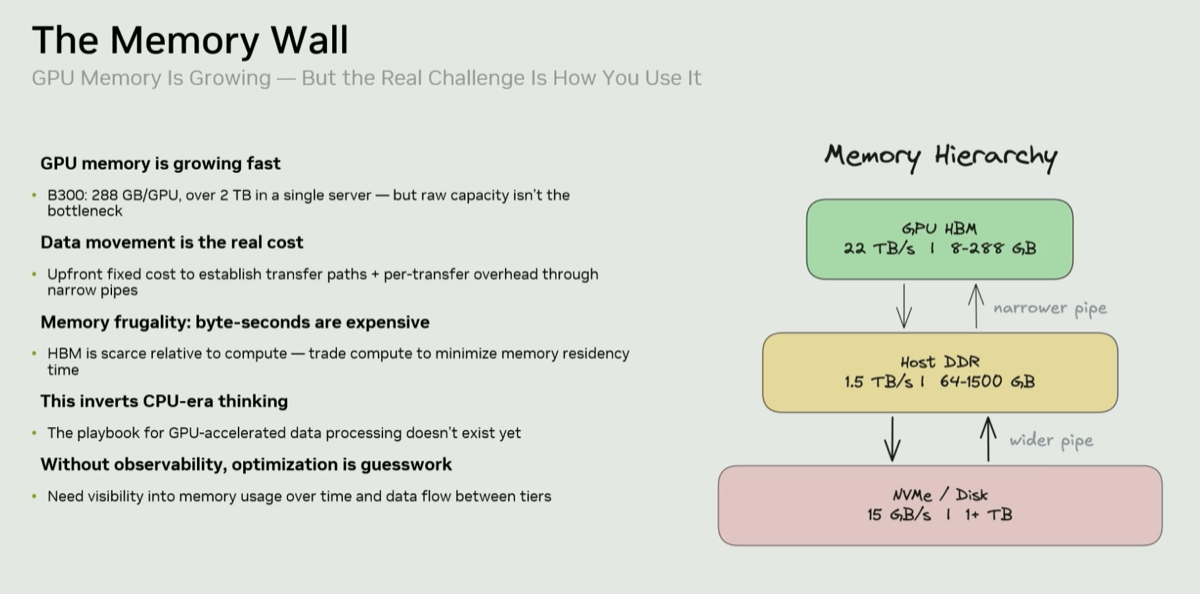
|
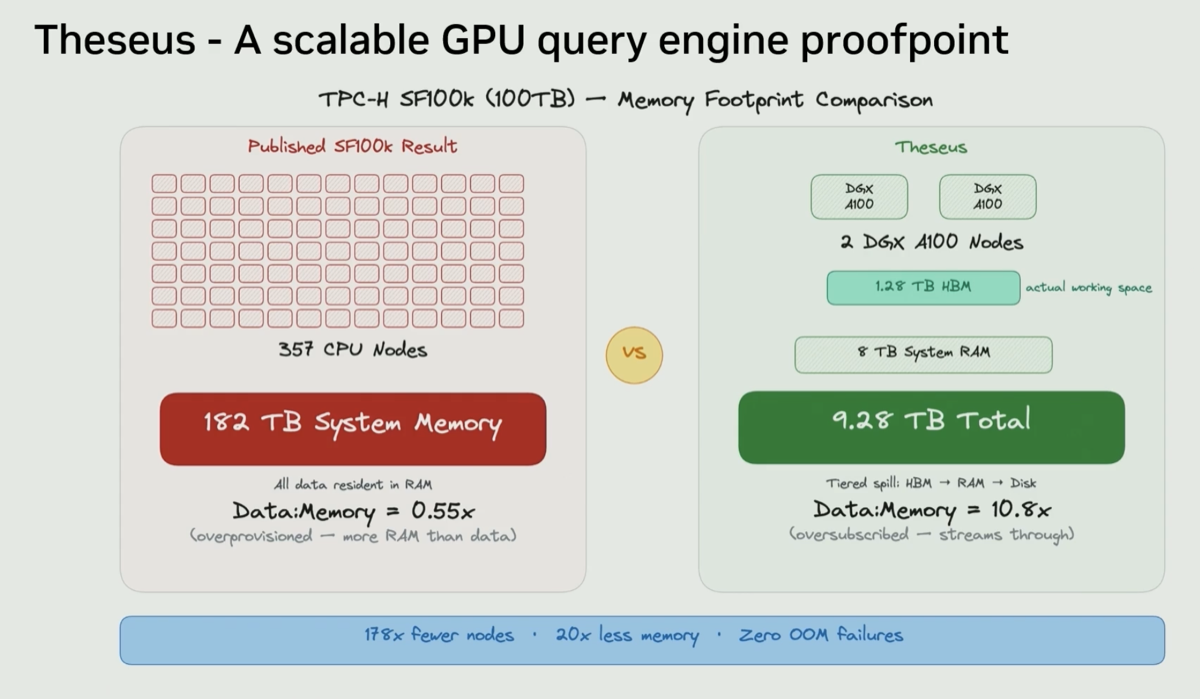
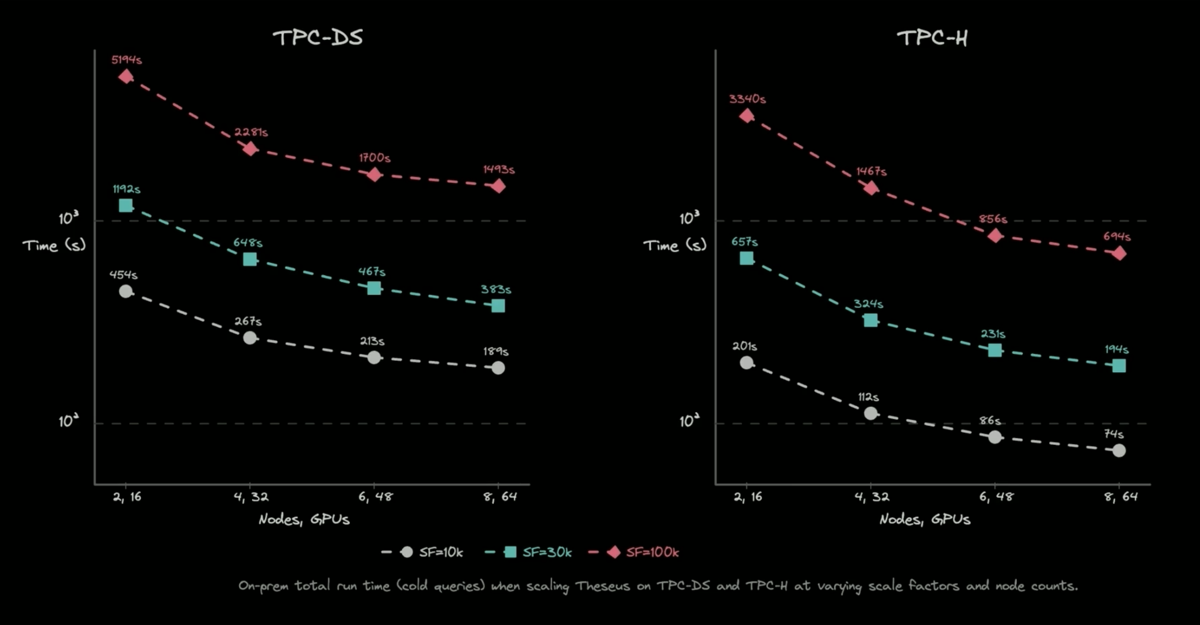
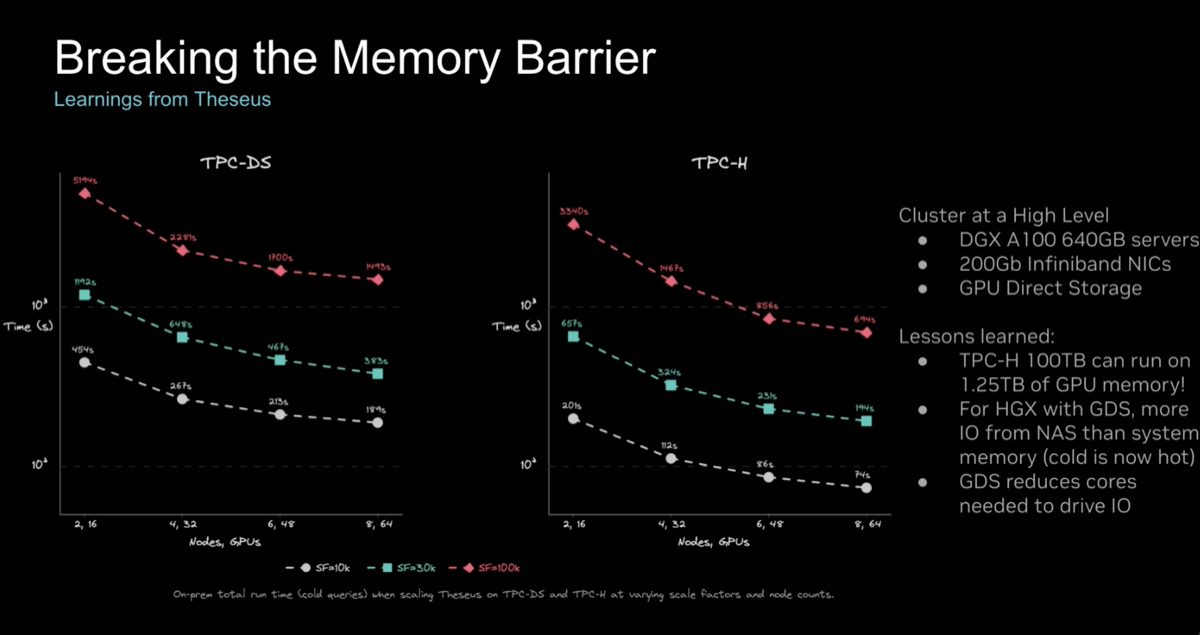
| 2. Theseus engine ran 100 TB TPC-H on 1.28 TB GPU working memory — 20× ratio via spill |
@ 03:09 |
|
Theseus — the research system behind cuCascade — processed the full 100 TB TPC-H/TPC-DS suite using only 1.28 TB of GPU working memory. With host memory (9.28 TB total), the effective data-to-GPU-memory ratio is roughly 20×. This is the existence proof for cuCascade's design: a single node can handle workloads orders of magnitude larger than its HBM capacity.
|
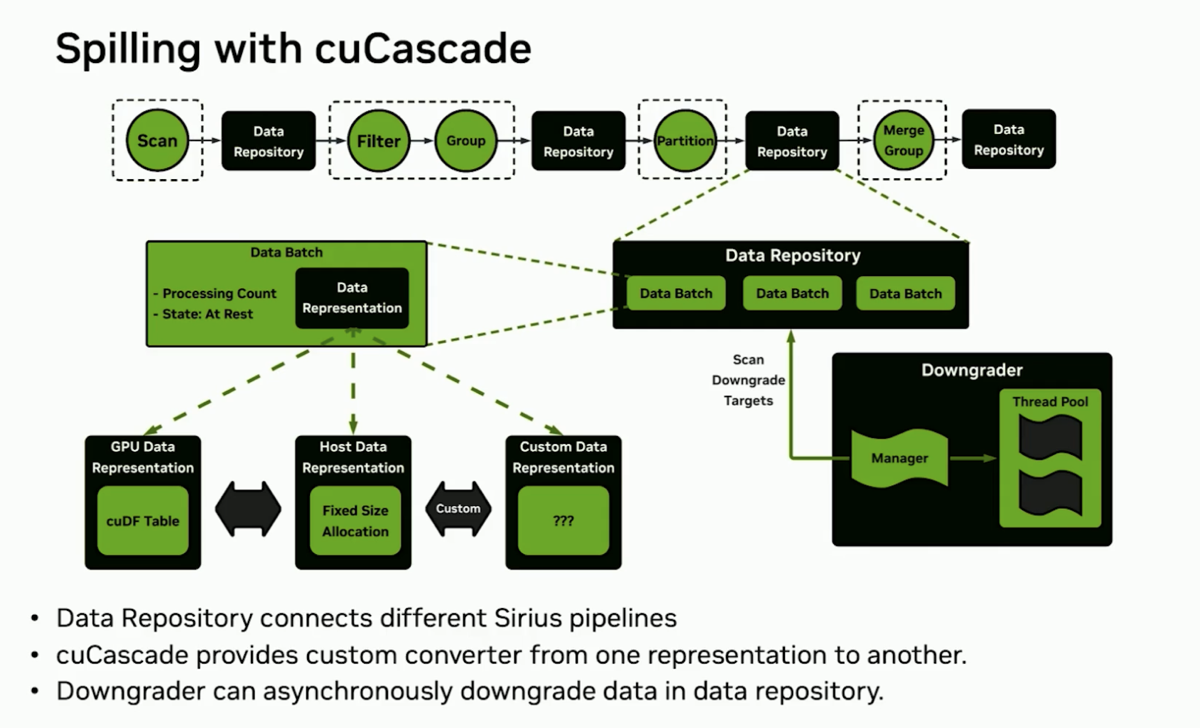
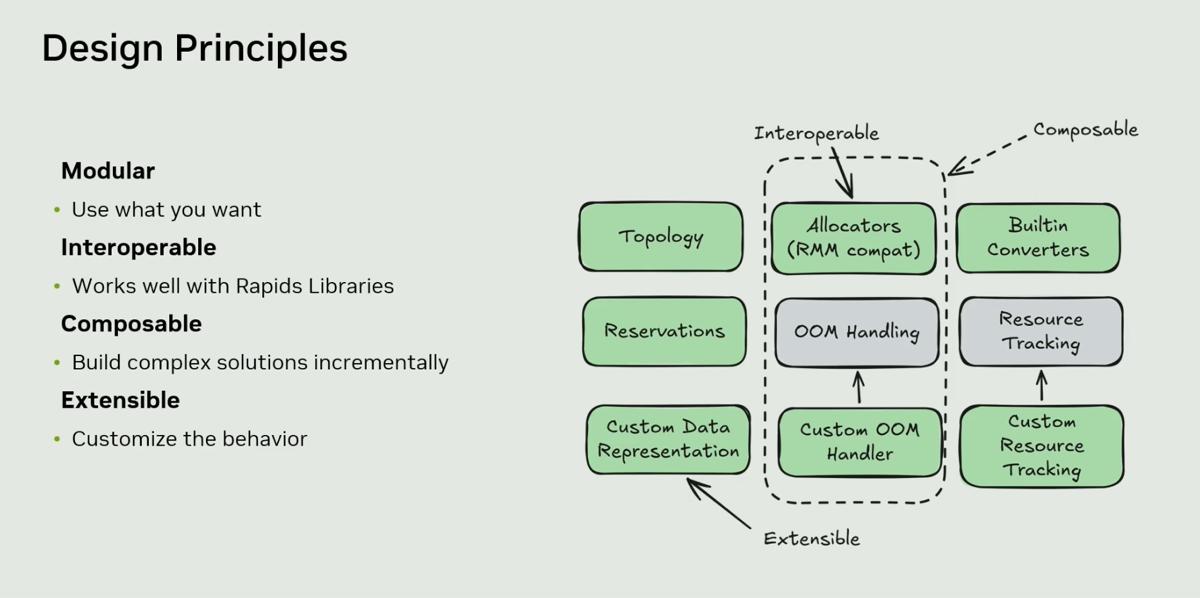
| 3. *cuCascade* solves topology, memory management, and data movement challenges using MICE design principles |
@ 05:00 |
|
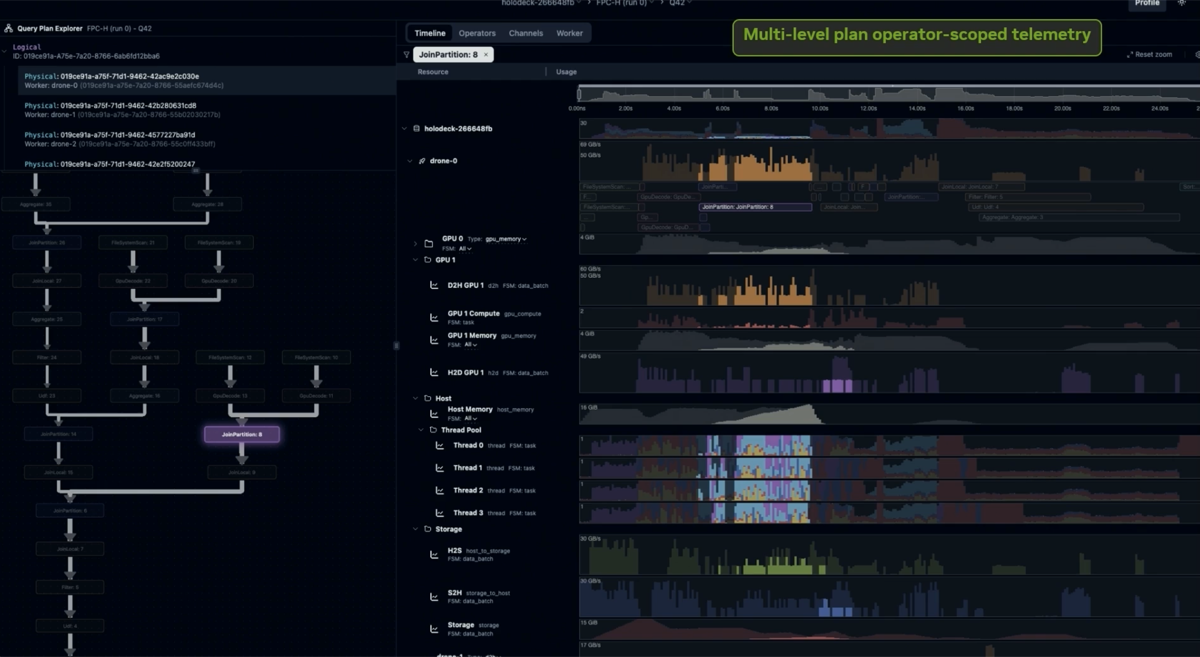
MICE: Modular, Interoperable, Composable, and Extensible enabling a multitude of use cases for cuCascade users: Engine developers can adopt it today to add multi-tier spill, memory reservation, and topology-aware scheduling without building these components from scratch, only choosing what they need or customizing for their use cases. Memory Reservation helps avoid oversubscribing memory and inevitable extra spilling and OOM. Allocation Policies are available to handle cases where Allocators reach their memory maximum. Data Format encoding, decoding, and conversion between different formats via Data Batch Representations (GPU cuDF Table, Host CPU fixed size pinned memory pages, custom). Automatic Topology discovery eliminates the human errors common with manual configuration file setup.
|
| 4. Sirius TPC-H-1k - Q9 required cuCascade's downgrade policy to pass |
@ 19:01 |
|
Sirius was one of the first projects to integrate cuCascade for spilling (another one is RAPIDS MPF, specifically used for multi-GPU data pipelines like shuffle). During the SF1K run, Query 9 was the query that most aggressively exceeded GPU memory — "that's the one that actually ended up blowing up on us quite aggressively." Without cuCascade's downgrade policy (which detects memory pressure and transparently degrades to host spill), the query would have OOM'd and terminated. The downgrade policy is what separates a working system from a fragile one. Note the focus on Query 9 from the Sirius team in their talk as well. cuCascade was built from a blank slate starting January 1st, 2026. Three months later it was live on stage. cuCascade made possible Sirius' performance on TPCH-1k of 21 seconds across all 22 queries on a GB300 DGX station, preventing OOM failures in the hardest queries.
|
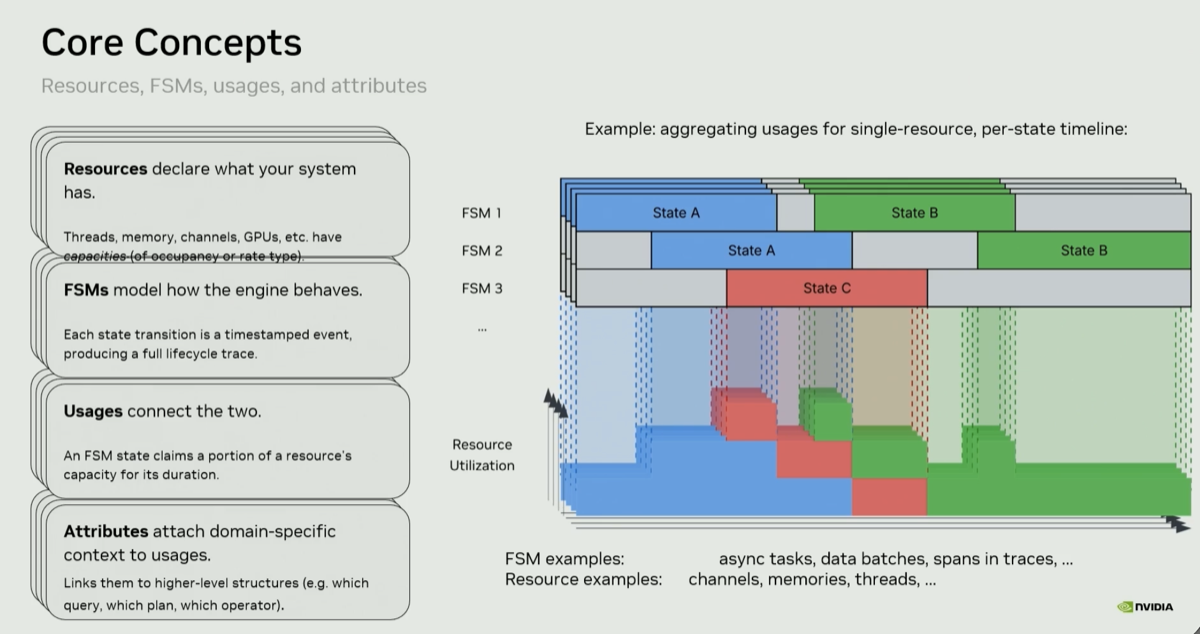
| 5. Built a custom telemetry tool at under 0.1% overhead - can be running in the background |
@ 22:58 |
|
The custom Rust-based telemetry layer captures cluster-wide data movement, per-operator throughput, and memory tier transitions with less than 0.1% runtime overhead — "you're not gonna have to pay this penalty." Existing tools (OpenTelemetry, Grafana, Prometheus, NSYS) were evaluated and rejected as too heavyweight for always-on use at this scale. The system was built from scratch specifically for distributed GPU analytics. Query plan operators can be mapped to the metrics collected during its run. Data movement can also be tracked as it moves across memory space. The tool has been used with SiriusDB.
|
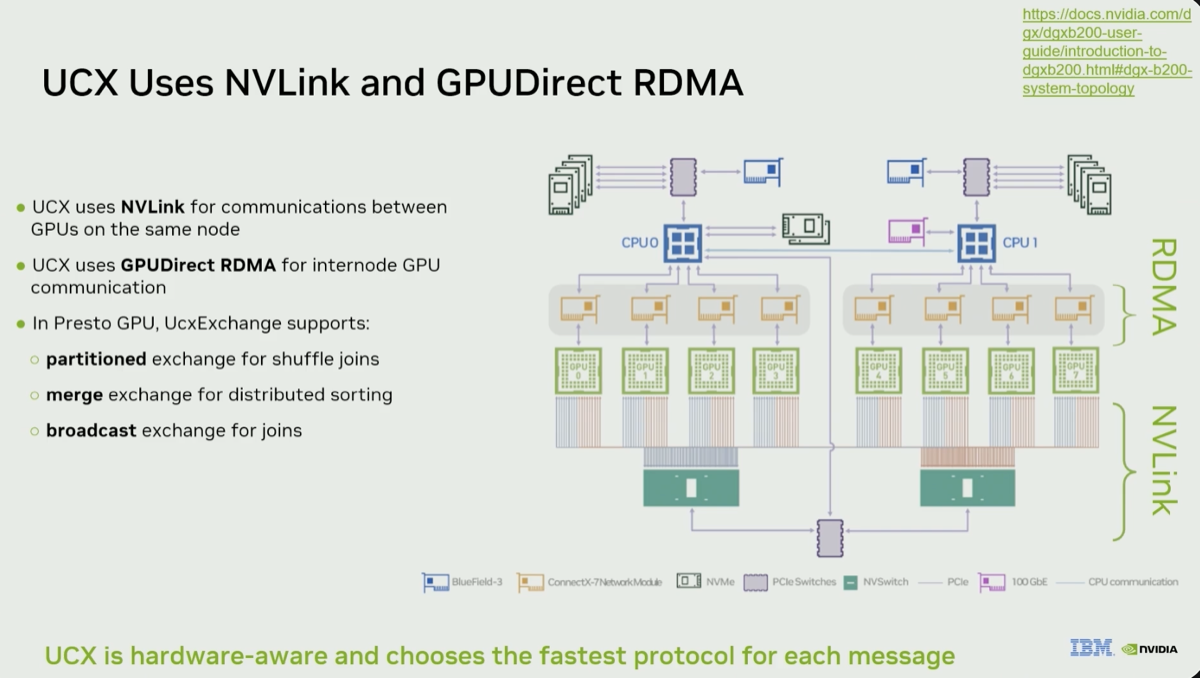
| 6. cuCascade makes cuDF multi-GPU — a capability cuDF doesn't have natively |
@ 36:06 |
|
Speakers highlighted recent progress improving libcudf, particularly the use of the recent nvcomp compression engine and support for new file formats like vortex. The evolution of cuDF could be more integration with cuCascade, providing the topology-aware routing and data movement layer that lets data operators cross the GPU boundaries. "cuDF itself is not intended to be a multi-GPU library. But leveraging it with cuCascade... you're able to do that multi-GPU computation with cuDF."
|
Cross-session themes
The four sessions share a common vocabulary captured in the takeaway tags. Here is what each theme amounted to across all sessions.
| I/O bottlenecks, missing UDF support, and undocumented cloud limits remain the main blockers to wider GPU analytics adoption |
- [GPU Era] CPU analytics is stagnating at 15–20% improvement per generation
- [GPU Era] 90% of enterprise data is unstructured and only 10% is properly indexed
- [GPU Era] At Airbnb, 2% of Trino queries consume 92% of cluster resources
- [Presto] Parquet I/O — not compute — is the dominant GPU analytics bottleneck
- [Presto] AWS S3 imposes an undocumented per-VM bandwidth ceiling
- [Presto] UDF support in libcuDF remains incomplete, blocking broader adoption
- [Sirius] Prior hybrid CPU-GPU scheduling research (Mordred, CoGaDB, HetExchange) produced too much complexity and too many performance cliffs
- [cuCascade] Existing observability tools (OpenTelemetry, Grafana, Prometheus, NSYS) are too heavyweight for always-on distributed GPU analytics
|
| Bandwidth, not compute, is the real cost; every layer of the stack is designed around moving fewer bytes faster |
- [GPU Era] Vera CPU provides 1.2 TB/s system BW and 14 GB/s per core — 3× that of x86/ARM
- [GPU Era] A100 HBM delivers 2 TB/s per GPU; NVLink 3.0 runs at 600 GB/s between GPUs — the combination made Theseus's 100 TB run viable
- [Presto] NVLink 5 on Blackwell achieves 1.8 TB/s bi-directional shuffle BW in Presto
- [Sirius] Sirius's pinned memory buffer doubles host-to-GPU transfer throughput on GB300
- [cuCascade] The cuCascade session framed bandwidth — not compute — as the primary cost of GPU analytics
|
| Spilling to host and NVMe makes workloads 20× larger than HBM viable on a single node |
- [cuCascade] Theseus processed 100 TB on 1.28 TB of GPU working memory — a 20× ratio via multi-tier spilling
- [cuCascade] cuCascade enforces memory reservation and allocation policies to prevent OOM before it occurs
- [cuCascade] During the live 21-second SF1K run, cuCascade's downgrade policy silently prevented Q9 from OOM-crashing
- [GPU Era] The SPACE MICE reference design projects 1.8 PB of NVMe per rack as queryable working memory
|
| NVLink and UCX abstractions make sub-100-second TPC-H at 1 TB possible across multiple GPUs |
- [GPU Era] NVLink 3.0 (600 GB/s) + InfiniBand (200 Gbps) made querying 100 TB on just 2 DGX nodes possible
- [GPU Era] SPACE MICE separates east-west NVLink shuffle (~1.8 TB/s) from north-south CX8 storage I/O (3–4 TB/s) — both networks run simultaneously without contention
- [Presto] Presto's UCXExchange selects NVLink when present and falls back gracefully to RoCE or TCP — proved decisive in slashing query times to 60 s
- [cuCascade] cuCascade adds topology-aware data routing that lets cuDF operators cross GPU boundaries — natively multi-GPU without cuDF itself being redesigned
|
| Parquet I/O dominates GPU analytics runtime; file format, encoding, and I/O coalescing are the primary tuning levers |
- [Presto] Parquet table scan accounted for 60–70% of runtime in Presto GPU — tuning is almost entirely an I/O problem
- [Presto] Delta Binary Packed encoding and NUMA pinning cut runtime by ~30% without changing any compute logic
- [Presto] Velox's async cache coalesces 700 small Parquet reads into ~200 large ones, dropping hot-run time to ~20 s
- [GPU Era] GPU Direct Storage makes petabytes of NVMe storage directly queryable GPU working memory
- [GPU Era] CX8 NICs in SPACE MICE are dedicated to north-south storage I/O at 3–4 TB/s
- [Sirius] Sirius bypasses the OS page cache by maintaining its own pinned memory buffer — data transfers in compressed form and decompresses on-GPU
- [cuCascade] cuCascade adds support for the vortex columnar file format
|
| Every engine chose clean separation of concerns: compute, spill, networking, and storage run as independent actors |
- [GPU Era] Theseus decomposed the monolithic executor into specialized actors — compute, prefetch, networking — to overlap I/O and compute
- [GPU Era] SPACE MICE separates east-west and north-south networks so NVLink shuffle never competes with storage I/O
- [Sirius] Sirius chose strict GPU-or-full-DuckDB-fallback, deliberately avoiding the hybrid scheduling complexity that plagued prior research
- [Sirius] Sirius separates the compute executor from the spilling executor so spilling can proceed concurrently with in-flight GPU computation
- [cuCascade] cuCascade follows MICE principles — Modular, Interoperable, Composable, Extensible — with a downgrade policy that handles memory pressure transparently
|
| GPU-native techniques (CAGRA, DBP encoding, read coalescing, memory frugality) compound hardware gains beyond raw clock speed |
- [GPU Era] CAGRA is a GPU-native graph nearest-neighbor algorithm that replaces CPU HNSW with 10–13× faster indexing
- [Presto] Delta Binary Packed encoding for integer columns makes Parquet data "scream fast on GPU"
- [Presto] Velox's async cache predicts required blocks via metadata reads and coalesces nearby fetches before issuing I/O
- [cuCascade] Memory frugality as an algorithmic inversion of the CPU paradigm: spend extra compute to shrink memory footprint and reduce access frequency
|
| A custom Rust telemetry layer, built because no existing tool was lightweight enough, runs at under 0.1% overhead |
- [cuCascade] Custom Rust-based telemetry layer captures per-operator throughput, cluster-wide data movement, and memory tier transitions — at under 0.1% runtime overhead
- [cuCascade] OpenTelemetry, Grafana, Prometheus, and NSYS were evaluated and rejected as too heavyweight for always-on distributed GPU analytics
- [cuCascade] The tool was used live alongside Sirius during the 21-second TPC-H SF1K run
|
| GPU analytics establishes new records at every scale factor, from 1 TB single-node to 100 TB multi-node |
- [GPU Era] CPU TPC-H results have flatlined at 15–20% generational improvement
- [GPU Era] Vera CPU delivers a 2.5–3× lift on TPC-DS with zero recompilation
- [GPU Era] CAGRA indexes 10–13× faster than CPU HNSW at equivalent accuracy
- [Presto] Presto GPU ran 30× faster than a Grace CPU cluster on SF1K; UCX exchange dropped TPC-H from 690 s → 453 s → 60 s
- [Sirius] Sirius completed TPC-H SF1K in 21 seconds across all 22 queries
- [cuCascade] Theseus ran the full 100 TB TPC-H/TPC-DS suite on a single node
|
| GPU instances at equivalent cloud cost deliver 7–10× the throughput of CPU alternatives |
- [GPU Era] Sirius delivers 7× TCO over cloud CPU on ClickBench
- [GPU Era] Vera CPU extends the story further with more GPU headroom per watt and zero recompilation cost
- [Presto] Presto GPU cuts cost-per-query by 10× vs. Presto CPU at SF1K, with the advantage growing for smaller clusters
- [Sirius] A GH200 at $2/hr delivers 9× the throughput of a comparably priced AWS CPU instance
|
| Sirius becomes an official DuckDB extension, cuCascade ships publicly, and OmniSci opens up in 2026 |
- [GPU Era] Heavy AI / OmniSci will be open-sourced in Q2 2026, bringing an LLVM compilation engine, Vulkan rendering, and geospatial/time series support
- [Sirius] Sirius is now the officially endorsed DuckDB GPU extension, announced on stage by DuckDB creator Hannes Mühleisen — "the blessed way of running queries on GPUs with DuckDB"
- [cuCascade] cuCascade is publicly available at github.com/NVIDIA/cuCascade, built from blank slate in three months
- [cuCascade] libcudf improvements and vortex file format support are community upstreamed
|
Part 2: Industry Use Cases and Training Labs →