This is Part 2 of my series on Accelerated Analytics at GTC 2026, focusing on 3 industry talks and 2 DLI training workshops. Read Part 1: Technical Deep Dives.
This post tackles the following sessions:
-
Quais Taraki (CTO, EDB) shows how standard Postgres breaks under agentic query loads and walks through PGAA — a GPU-accelerated HTAP solution that swaps the Postgres compute back-end for Iceberg + Spark RAPIDS, achieving 100× TPC-DS speedup and enabling a complete LangFlow-based agentic stack on top.
-
Liang Chen and Prudhvi Vatala from Snap detail how Spark RAPIDS cut A/B pipeline costs by 90% — not through any Spark tuning magic, but by rerouting 11,000 idle inference L4s into a three-tier fallback Spark fleet at near-zero incremental cost.
-
Harishankar G and Jalakandeshwaran A from Zoho give a deep dive into Velociraptor, their in-house GPU OLAP engine built as a Postgres extension, which runs all 22 TPC-H queries at 1 TB on a single H200 in under two minutes — then explain why PCIe is still the bottleneck even after every I/O optimization.
-
Hirakendu Das, Navin Kumar, and Rishi Chandra lead a hands-on Spark RAPIDS workshop covering the cuDF plugin, Project Aether’s automated qualify → tune → validate loop, and Ether Assistant’s LLM-based UDF rewriter.
-
Allison Ding walks through a full GPU data science pipeline — from zero-copy feature engineering with cuDF and GPU Polars, through cuML model training (k-means 40×, XGBoost 7×), to Triton Inference Server deployment with dynamic batching.
Industry Use Cases
Quais Taraki · CTO, EDB
NVIDIA Session overview
As data volumes increase, the primary bottleneck for high-performance AI agents will shift from the model to the data. This increases the importance of the underlying data engine’s ability to process massive enterprise datasets in real time. This scaling problem is further amplified by the desire to make the latest transactional business data seamlessly available to agentic processing. Join the experts from EDB for a technical deep dive into how to overcome these scaling and transactional integration hurdles using the world's most popular open-source database. We will showcase the architecture behind GPU acceleration in EDB Postgres AI, specifically how offloading complex analytical workloads to an NVIDIA RAPIDS Accelerator for Apache Spark eliminates traditional CPU bottlenecks. Through a review of TPC-DS benchmarks, we will demonstrate how to transform Postgres into a high-throughput engine capable of powering autonomous agentic analytics for real-time business decision-making. We will also showcase how EDB Postgres makes all transactional data available to GPU processing in real time through Apache Iceberg. This establishes a GPU-accelerated Hybrid Analytics and Transactional Processing (HTAP) stack, which at the same time avoids vendor lock-in by being fully compatible with the modern open analytics ecosystems.
EDB (EnterpriseDB) develops solutions on top of PostgreSQL, such as the proprietary extension PostgreSQL Analytics Accelerator (PGAA) discussed in this talk. EDB recognizes the problem that Analytics Agents are now bottlenecked by CPU-based data systems for their OLAP needs. In this talk, Quais discusses PGAA, their hybrid OLTP/OLAP solution that relies on Spark Rapids GPU acceleration for large-scale analytics and making it available to Agents via technologies like langflow and kserve. More on PGAA in their blog post.
Takeaways
| 1. Agent queries time out on standard Postgres — the database becomes the bottleneck |
@ 03:54 |
Agents generate far more complex and random query patterns than human-written queries. "We see customers hitting timeouts with large data sets, thereby starving the agent." Constraining the agents or doing an application rewrite are the typical mitigations — both undesirable. The fix must come from the database layer.

|
| 2. PGAA swaps the Postgres compute back-end: Iceberg + DataFusion + Spark Connect on RAPIDS |
@ 05:11 |
EDB's Postgres Analytics Accelerator (PGAA) replaces the Postgres compute back-end with three components: (1) replicate data to object storage in Apache Iceberg format; (2) DataFusion — "a columnar vectorized open source query engine" — as a plug-and-play compute layer; (3) Spark Connect to offload massive distributed joins to a Spark cluster, further accelerated via Spark RAPIDS on GPU. The Postgres front-end and SQL interface remain unchanged.
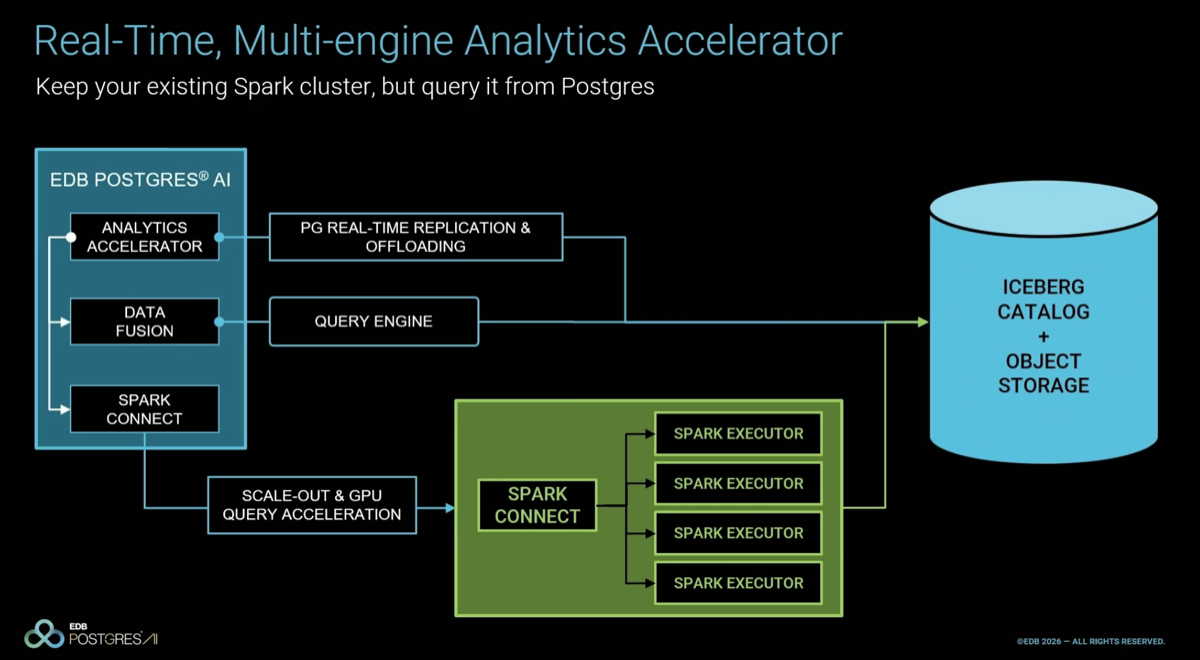
|
| 3. TPC-DS: Postgres times out at 10 TB; Spark RAPIDS on L40S is 100× faster; Blackwell adds 14× more |
@ 05:57 |
Three-tier TPC-DS comparison across data sizes: standard Postgres (orange) grows unbounded and times out at 10 TB; vanilla Spark+PGAA (blue) is a substantial improvement; Spark RAPIDS on L40S (green) lands "on the order of 100x over standard Postgres." Re-ran on RTX 6000 Pro (Blackwell): "a further 14x speedup" on top of that.
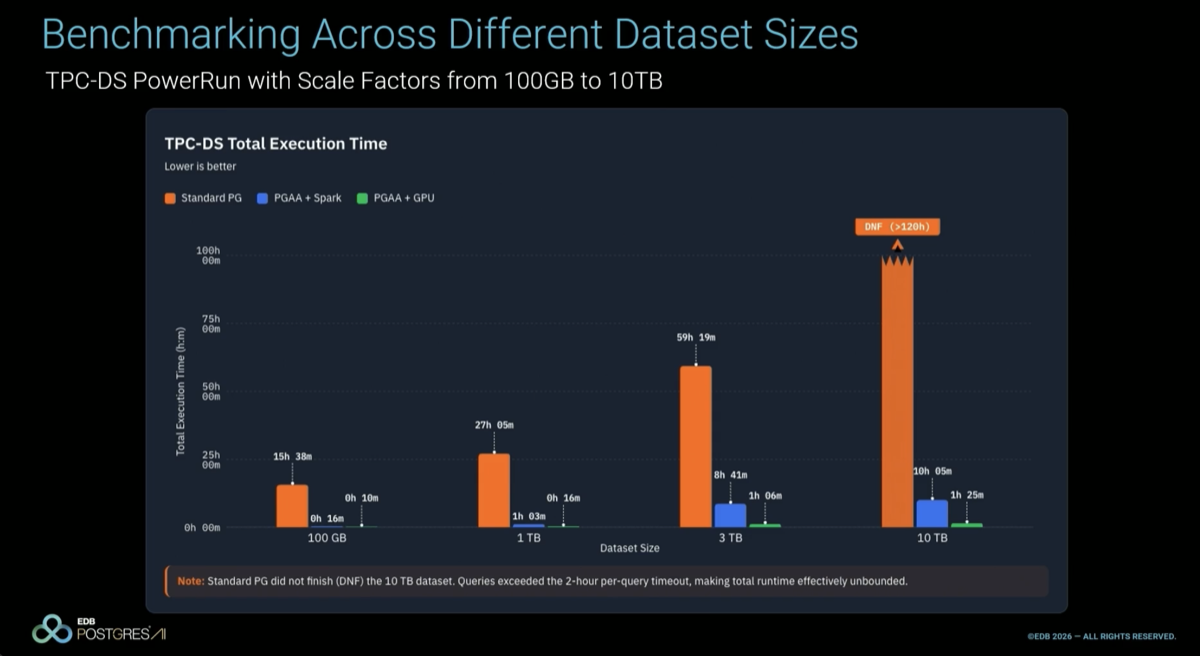
|
| 4. Full agentic stack: AIDB vectorization + MCP endpoints + NVIDIA NIMs + LangFlow on top of PGAA |
@ 08:02 |
|
Above the analytics layer: the AIDB extension generates embedding vectors from Postgres data for semantic search; MCP endpoints expose all data stores to LLM agents; containerized NVIDIA NIMs run local model inference via KServe; LangFlow provides a low/no-code agent authoring environment. The entire stack runs on NVIDIA GPUs. Speaker's admission: "there are a lot of moving parts… a lot of security to consider" — EDB packages all of it so customers don't have to.
|
| 5. EDB ships the full stack as a sovereign, batteries-included Postgres platform |
@ 09:41 |
Stack choices are opinionated: Lakekeeper as the Iceberg catalog ("a much more modern version than, say, something like Hive Metastore"), LangFlow for agent authoring, NVIDIA NIMs on KServe for inference. The platform is "complete, batteries included, modular, composable, sovereign, open source" — deployable on IBM mainframes, on-premise, all hyperscalers, or custom Supermicro+NVIDIA hardware.
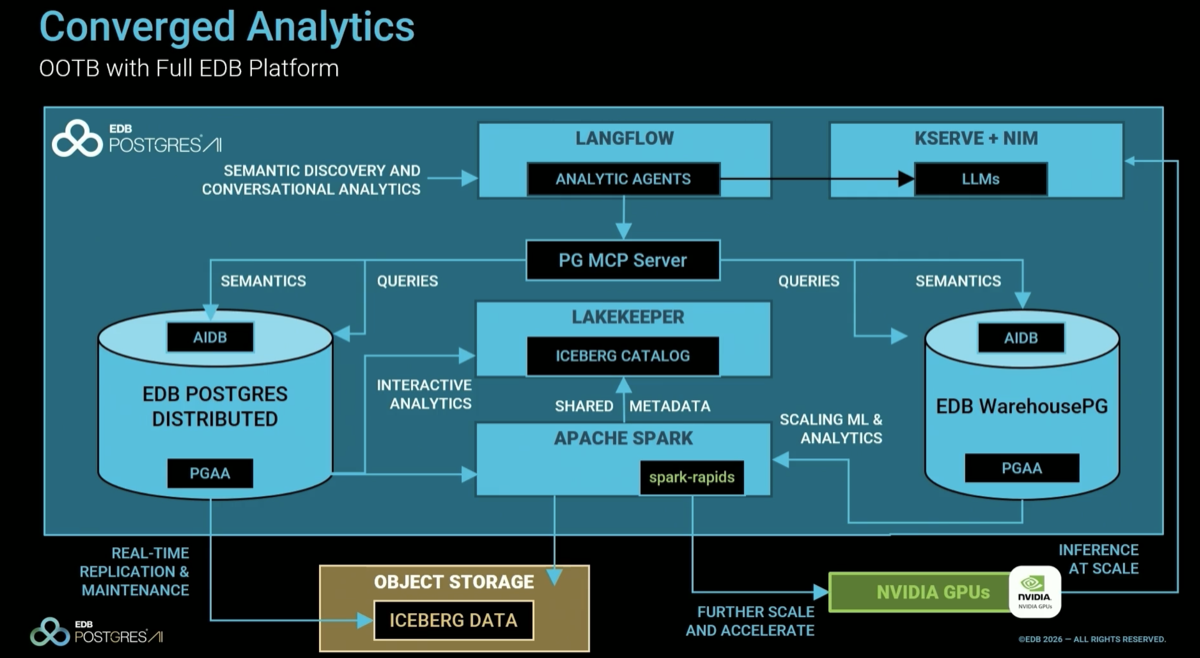
|
Liang Chen · Staff Software Engineer, Snap, Inc.
Prudhvi Vatala · Sr. Engineering Manager, Snap, Inc.
NVIDIA Session overview
Snap's A/B experimentation platform processes 10 petabytes per day across ~45,000 machines with a strict 11 AM SLA and zero tolerance for failure. This talk is an eight-month engineering journey: from discovering the RAPIDS Spark accelerator, through benchmarks, infrastructure blockers, and a novel GPU reuse strategy, to a fully productionized petabyte-scale GPU Spark platform that cut costs by 90%.
This session takes us through Snap’s experience adopting Spark on RAPIDS for its A/B pipelines. All these experiments were done on GCP instances featuring L4 and T4 GPUs like the g2-standard-48, with an on-demand price of $1.76. Interestingly, using Spark on RAPIDS was mostly a smooth experience with little engineering effort; the main bottleneck was rather the scarcity of GPUs available for these data processing jobs, at a time when almost everything is going toward AI inference and training. The team’s main engineering effort was thus moving their system over to the AI K8s GKE cluster to take advantage of the idle GPUs often seen late at night. Nevertheless, the team highlights their collaborative effort with Google and NVIDIA in getting this to work. Look at this companion article from Snap Engineering for a good read.
Takeaways
| 1. Non I/O-bound jobs saw significant speedups with Spark Rapids, particularly in join and repartition stages |
@ 04:21 |
|
For the merge sort join operator on 3 TB of input, total Spark execution time dropped 20×, leading to a wall-time speedup of 2.5×. For the union operator on 9 TB of input, total Spark execution time dropped ~4×, for a wall-time speedup of 1.8×. Aggregation's wall-time speedup was 1.6×. The authors note that in the first two cases, the speedup was due to no longer seeing terabytes of data spilling onto disk when using RAPIDS.
|
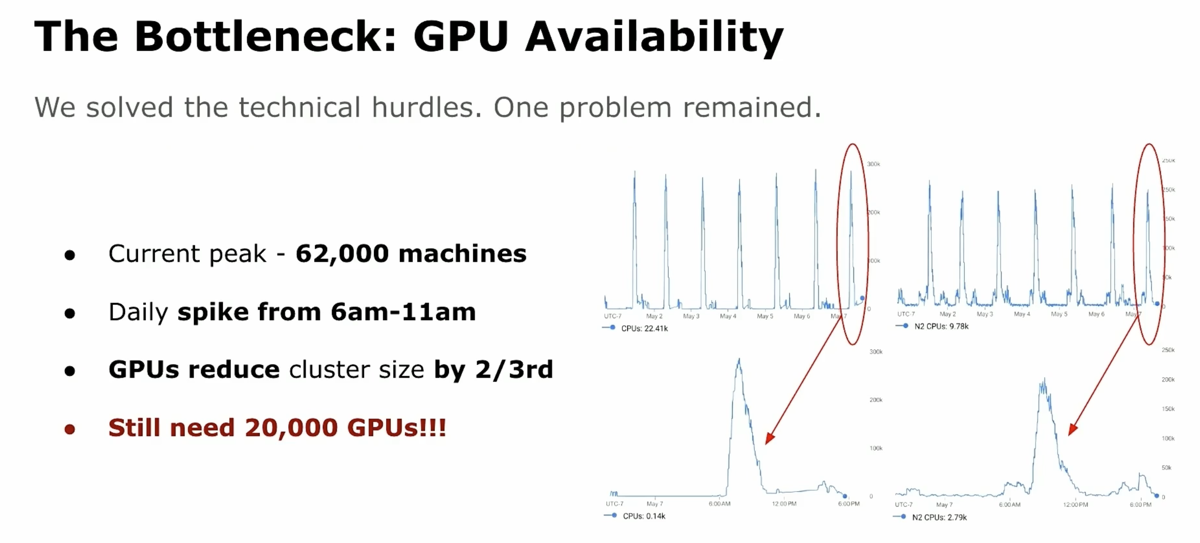
| 2. At Peak, the actual bottleneck is GPU Availability! |
@ 08:54 |
|
A/B cluster uses 60k machines to finish within its time window. GPUs would reduce peak machine count by two-thirds — from 62,000 to ~20,000 GPUs simultaneously, still a huge amount! On-demand GPU procurement at that scale was not feasible. The breakthrough was finding idle capacity already inside Snap: the ML inference fleet for ad ranking and content recommendations drops to low utilization between 2–5 AM Pacific as users sleep, leaving thousands of GPUs sitting idle every night.
|
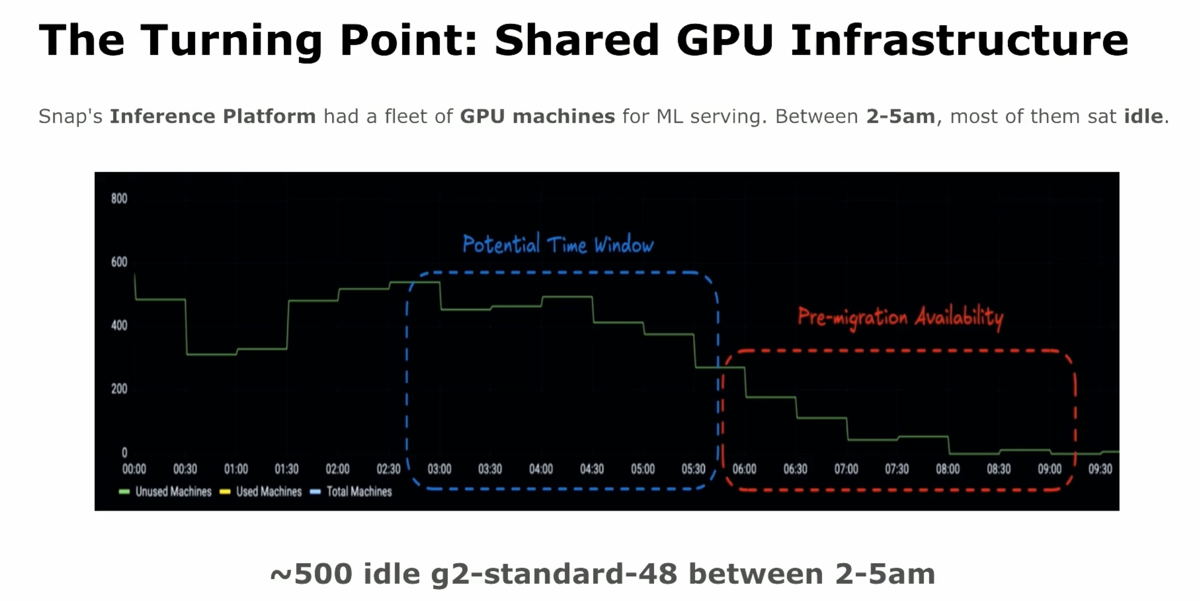
| 3. Reusing the inference fleet's idle window — the unlock for scale |
@ 11:12 |
|
Snap built a Spark-on-GKE platform that runs batch jobs on the same infrastructure as the serving stack. Jobs use GPUs only when available and fall back to CPU GKE, then Dataproc — "GPU acceleration is just opportunistic, never mandatory." Pipelines were shifted into the 1–5 AM idle window by moving from client timestamps to server timestamps and rescheduling upstream Airflow dependencies to start at 2–3 AM.
|
| 4. Three-tier fallback: GPU GKE → CPU GKE → Dataproc; no job ever fails to complete |
@ 15:46 |
|
At submission: no GPU quota → fall back to CPU Kubernetes. At runtime: GPU preempted by serving traffic → retry on GPU GKE, then CPU GKE, then Dataproc. "Every single job has a path to completion." Production shows 99% hourly job success rate and 96% daily — "and these numbers aren't even cherry picked. These numbers include all the infra failures even beyond GPUs."
|
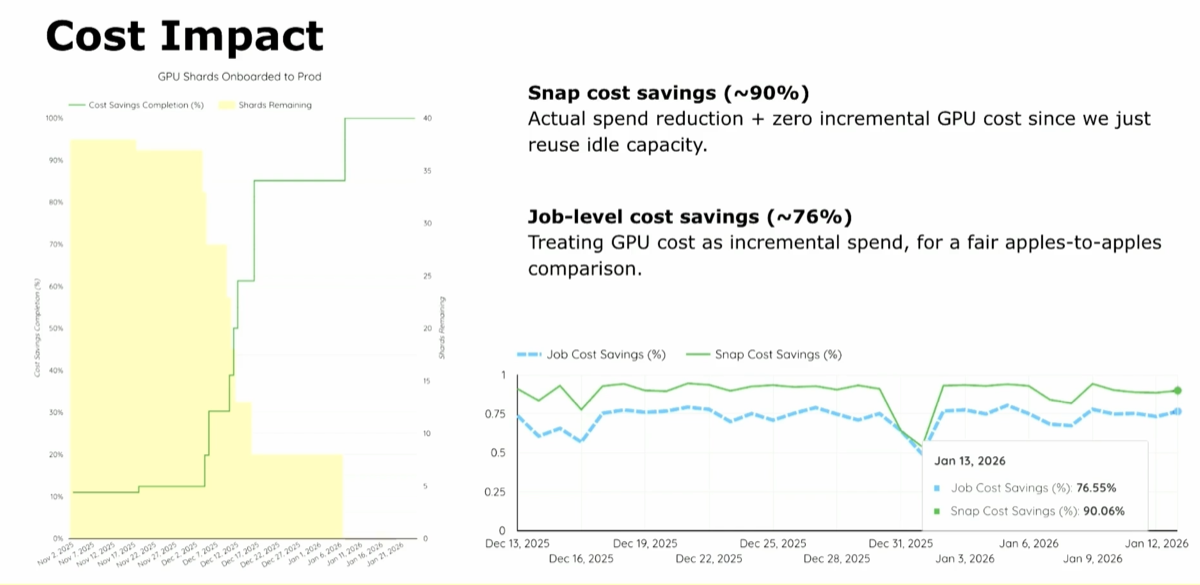
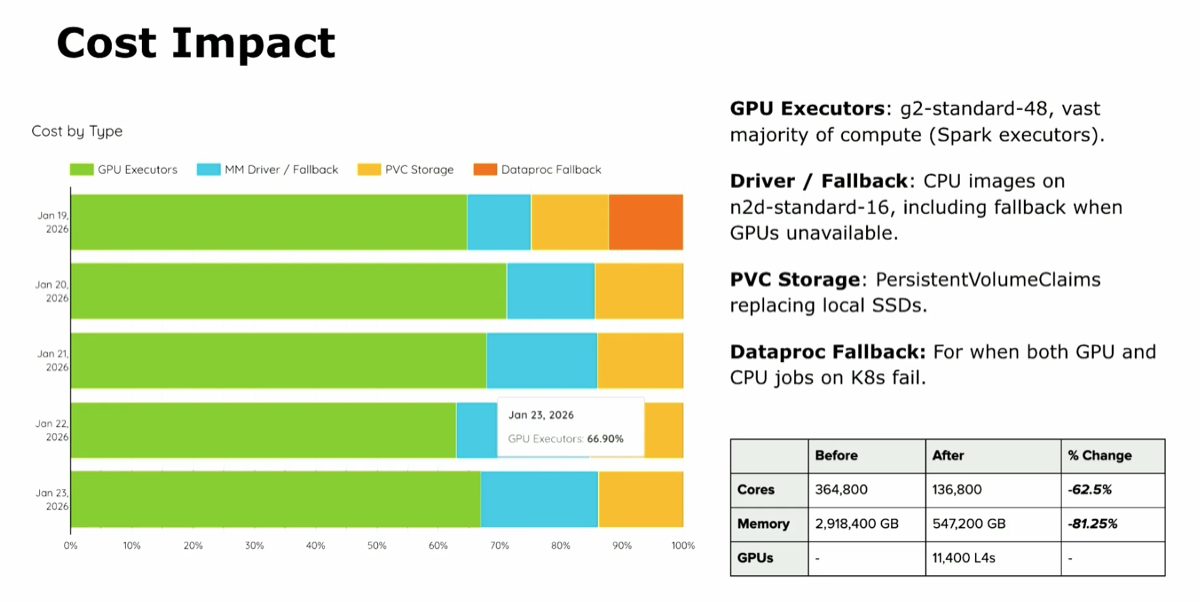
| 5. 90% net cost reduction; 11,000 L4s, 81% less memory, zero new spend |
@ 22:15 |
|
Because Snap reuses idle capacity, "there is no net new compute cost added." Net experimentation platform footprint dropped 90%. Apples-to-apples (counting GPU cost as incremental): 76% savings. The switch to g2-standard-48 instances leads to a dramatic drop in resource usage and costs: the pipeline now runs on ~11,000 L4s during the six-hour overnight window, "number of cores went down 62.5%," "memory went from about three petabytes to half a petabyte, 81% reduction."
|
Harishankar G · Leadership Staff, Zoho Corp.
Jalakandeshwaran A · Leadership Staff, Zoho Corp.
NVIDIA Session overview
Join us for a deep dive into how data-intensive workloads can be accelerated using GPUs. This session explores the inner workings of a GPU-accelerated query pipeline that offers excellent performance by leveraging custom kernels and NVIDIA libraries like Thurst and nvCOMP. Learn how data transfer becomes the primary bottleneck, and how faster interconnects like NVLink and GPU-accelerated decompression help mitigate the issue.
Takeaways
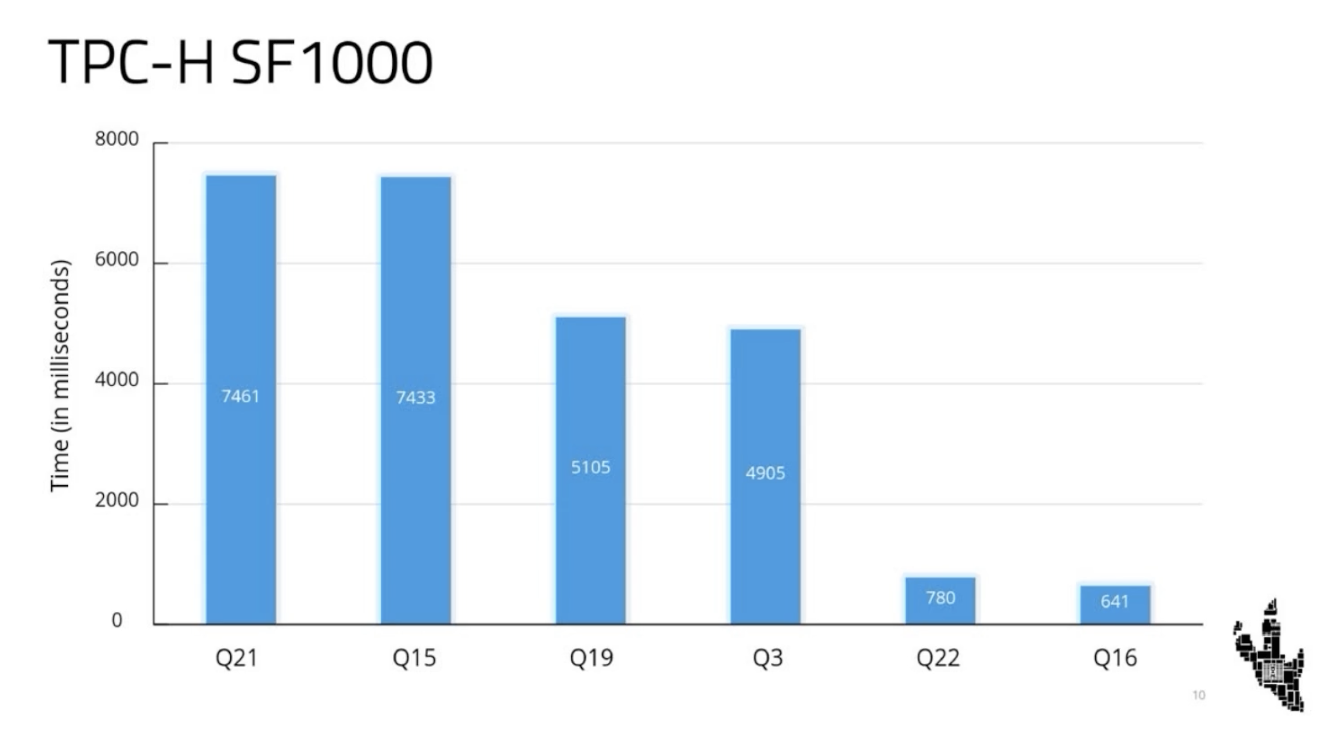
| 1. Velociraptor processes all 22 TPC-H queries at SF1k (1TB) in under 2 minutes on a single H200 GPU |
@ 03:37 |
|
Zoho's in-house GPU-accelerated OLAP engine, shipped as a Postgres extension, runs the full TPC-H benchmark at scale factor 1000 on a single GPU with 90 GB of memory. "The longest query executes in under eight seconds. The shortest one runs in under a second. And the median query execution time is five seconds." It currently powers Zoho Analytics' largest customers.
|
| 2. Plan conversion layer decouples GPU-optimal rewrites from the Postgres front-end and keeps the original plan for OOM fallback |
@ 04:48 |
|
Postgres selects hash vs. sort group-by based on work_mem and expected cardinality — optimal for CPU, not for GPU. A plan conversion step lets Velociraptor substitute GPU-optimal choices while keeping the original Postgres plan intact for OOM fallback: "allows us to keep the original plan untouched in case we need to fall back due to situations like out of memory." It also let the team switch from Apache Calcite to Postgres as the front-end with minimal changes to code generation and execution layers.
|
| 3. Four-layer I/O stack: columnar storage + block filtering + compression + late materialization — all to minimize bytes sent to the GPU |
@ 06:27 |
|
Techniques compound: (1) column-store layout skips unneeded columns; (2) per-block min/max metadata prunes blocks that can't pass a filter without reading them; (3) columnar layout boosts compression ratios since same-type data compresses better; (4) late materialization fetches only columns needed for the current operator. The result: sometimes only a very small amount of data per batch actually crosses the PCIe bus.
|
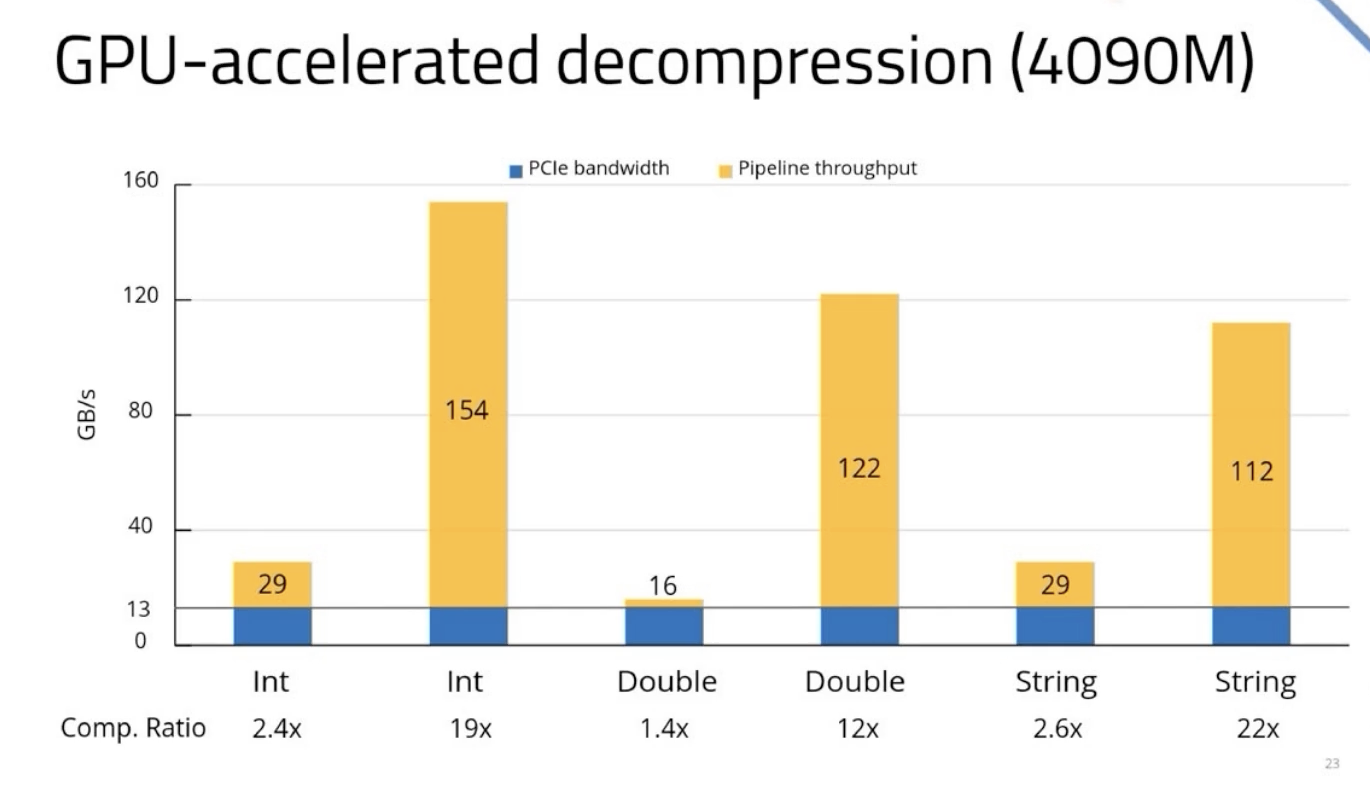
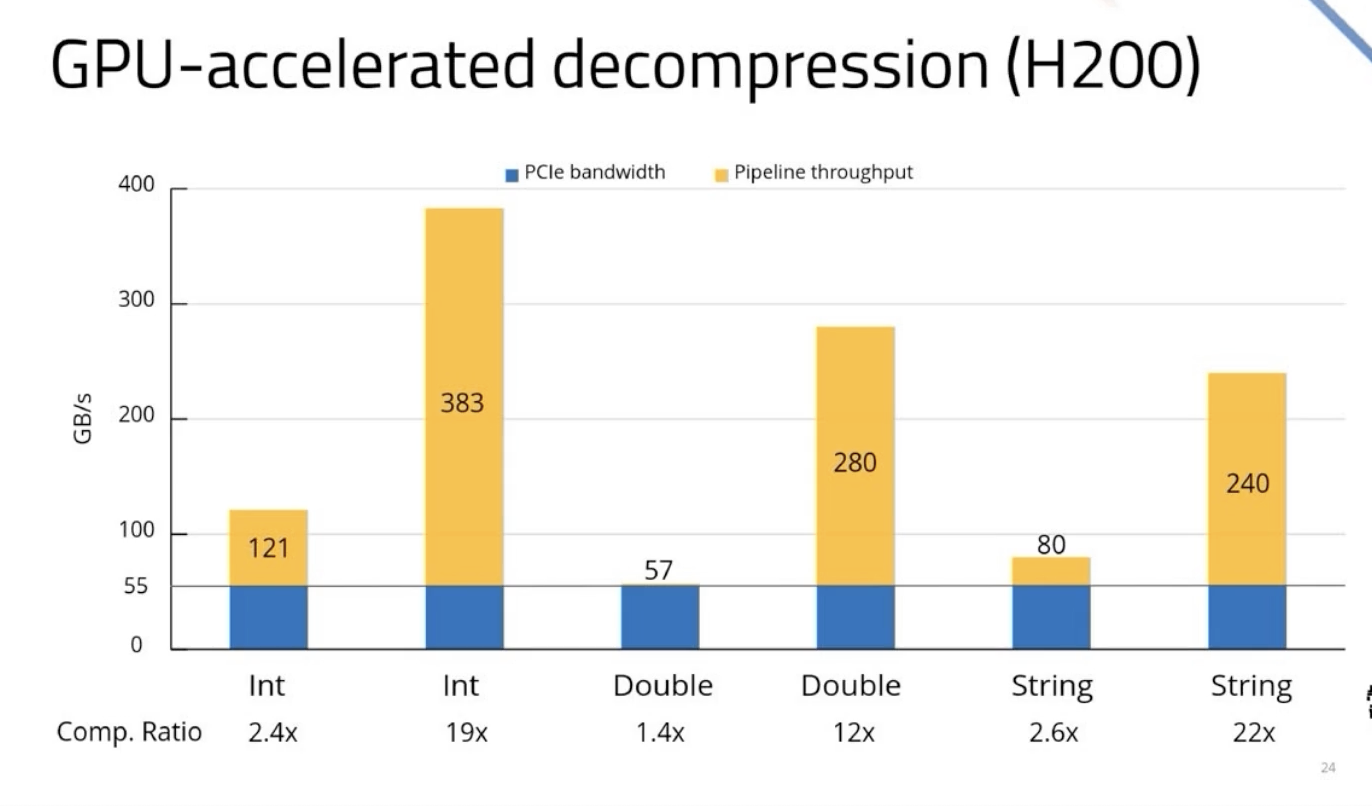
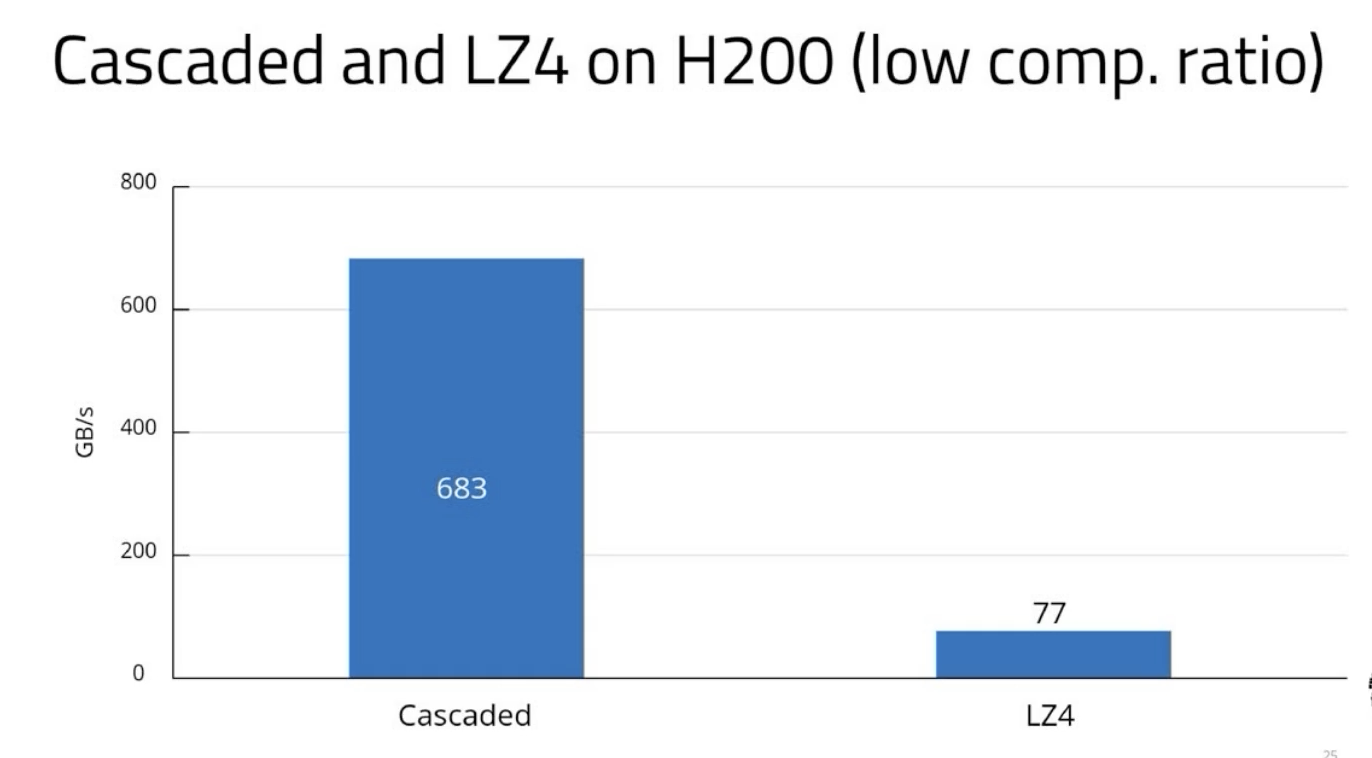
| 4. GPU decompression blows past the PCIe limit for high-compression data; LZ4 for strings is the weak link |
@ 10:23 |
|
A three-stage pipeline — disk read → PCIe transfer → GPU decompress — runs concurrently using nvCOMP. On PCIe Gen 4 x8 (13 GB/s cap), GPU-accelerated decompression of cascaded RLE/delta columns exceeds the interconnect ceiling for highly compressed data. On H200 (PCIe Gen 5, 58 Gbps; 8.5× the memory bandwidth of the previous system), numbers are similarly strong. Weak link: LZ4 used for strings and doubles has lower throughput at low compression ratios — Blackwell's on-chip LZ4 decompressor is on the team's roadmap.
|
| 5. Even after all optimizations, GPU execution is only 25% of end-to-end query time — PCIe is still the bottleneck |
@ 12:15 |
"Despite all of these optimizations… the actual time spent on executing the query on the GPU in a benchmark like TPC-H is only 25% of the end-to-end time. So we are still bottlenecked by the interconnect and decompression." The team is explicitly waiting for NVLink as a CPU-to-GPU interconnect on x86 — NVLink already reaches 900 GB/s for hosted devices vs. PCIe Gen 6 at 128 GB/s. They welcomed the Intel/NVIDIA NVLink fusion partnership as a step in that direction.
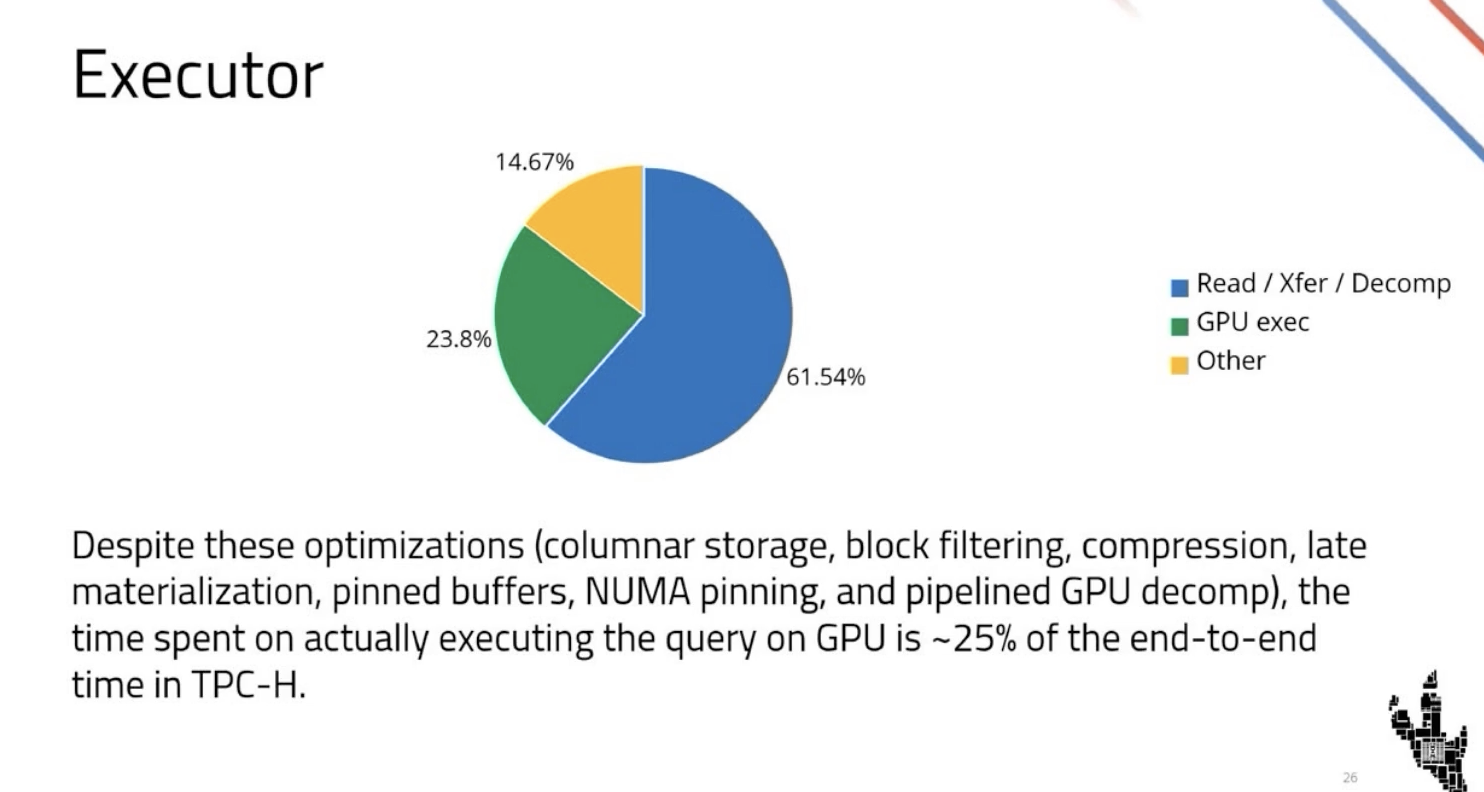
|
DLI Training Labs
Hirakendu Das · Principal Software Engineer, NVIDIA
Navin Kumar · Sr. System Software Engineer, NVIDIA
Rishi Chandra · Systems Software Engineer, NVIDIA
NVIDIA Session overview
A hands-on DLI workshop covering three layers of GPU-accelerated Spark: the RAPIDS cuDF plugin (zero-code-change columnar acceleration), Project Aether (automated qualification, testing, and migration toolchain), and Ether Assistant (LLM-based UDF rewriter). Uses the NVIDIA Decision Support (NDS) TPC-DS-derived benchmark throughout.
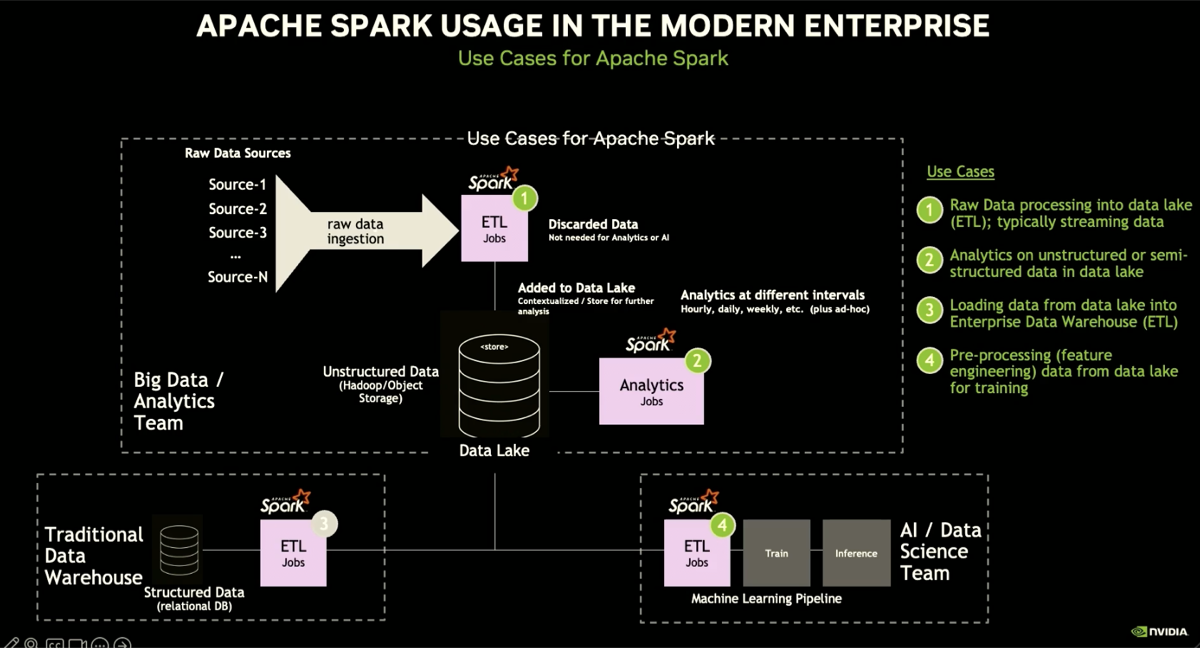
Apache Spark usage is predominant in enterprise. Four different use cases are highlighted at the beginning of the training session to remind us how central the system is and how enabling RAPIDS on Spark has wide impact across enterprise operations:
- RAW ETL into the data lake
- Analytics on this ingested data
- Loading data from the lake into traditional data warehouses
- Pre-processing this data for machine learning training and other data science use cases.
Takeaways
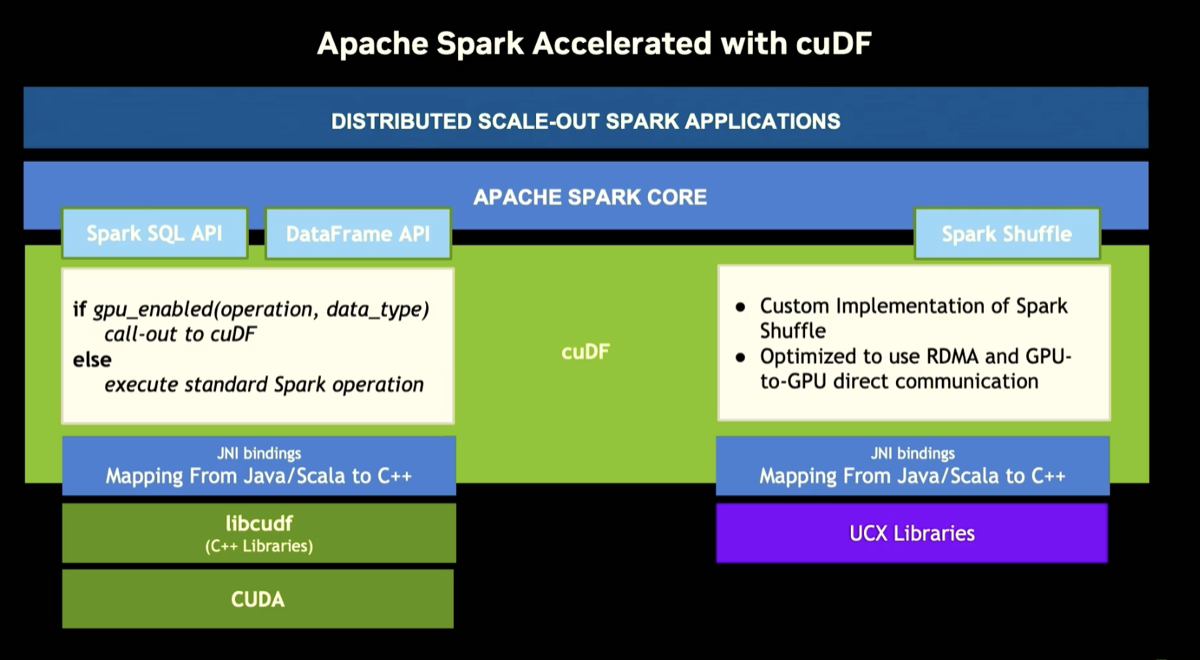
| 1. cuDF is the CUDA library at the center of RAPIDS Spark |
@ 07:41 |
|
cuDF implements relational algebra on the GPU. Each node will convert the Spark physical plan into a plan that can be run over CuDF. Data is stored in columnar format and remains so until an unsupported operator forces a CPU fallback. The cost is the conversion round-trip not the operation itself. The RAPIDS qualification tools help determine if the overall query will overcome these challenges or not.
|
| 2. Spark on GPU wins on compute intensive tasks like joins, aggregates, sorts over high-cardinality data — not I/O-bound ops |
@ 12:18 |
|
"If you have systems with very large amounts of high cardinality data.. and joins and aggregates and sorting, those tend to be the most ideal workloads for GPU." I/O-bound jobs, where most time is spent reading from or writing to a data store, see little benefit. Small datasets also underperform due to the overhead of staging data into GPU memory. Know which regime your job is in before expecting a speedup.
|
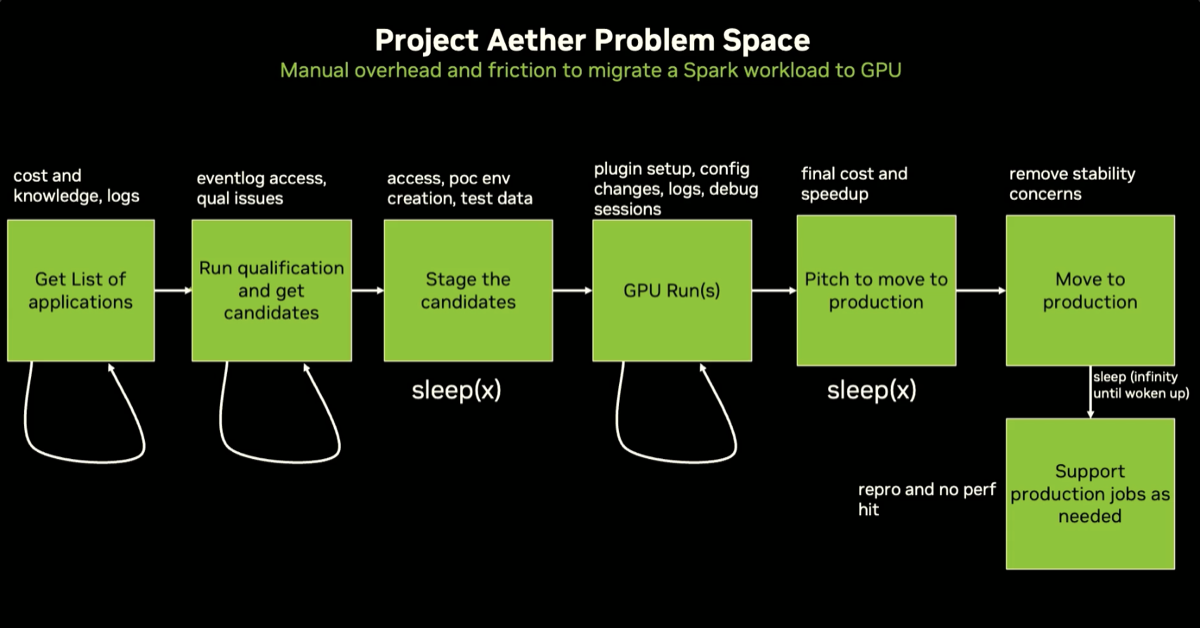
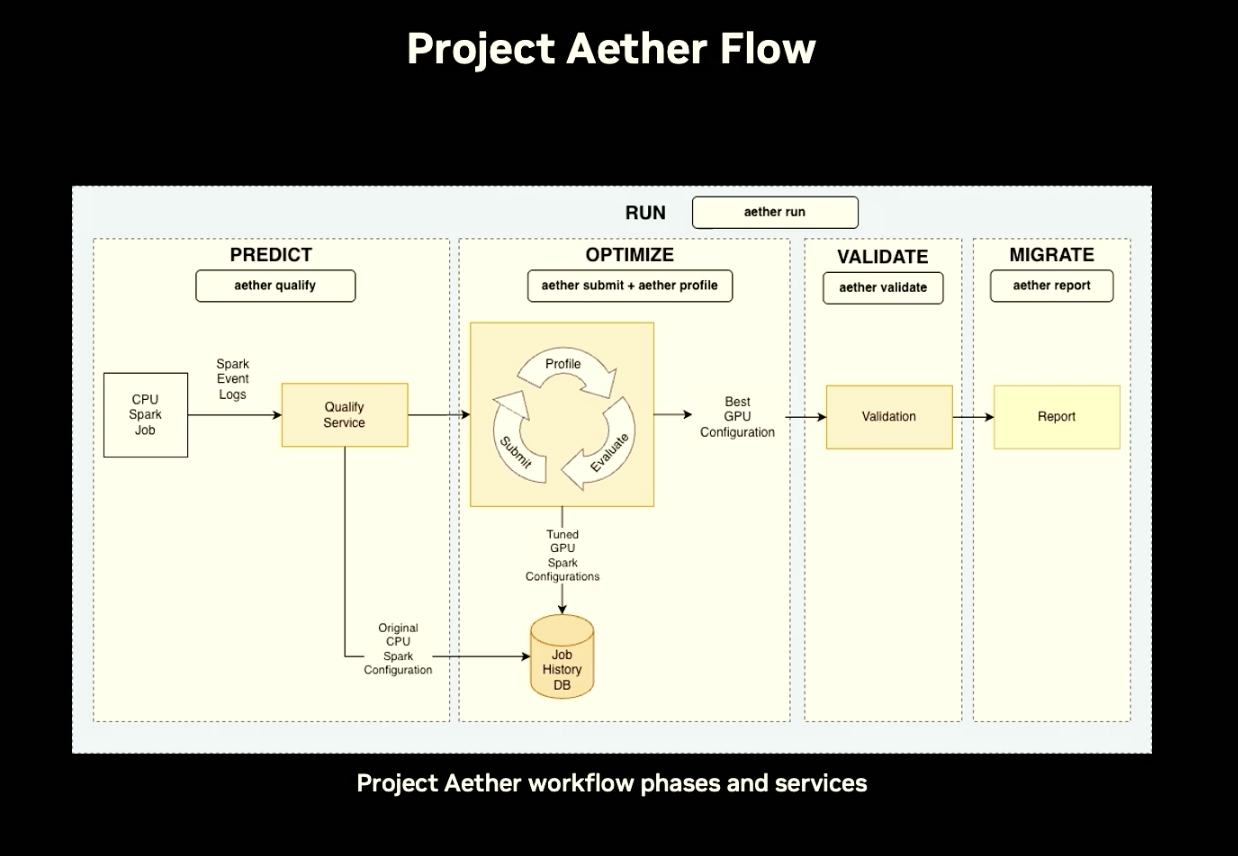
| 3. Project Aether automates the full qualify → submit → profile → tune → validate loop |
@ 13:56 |
|
The old manual migration process — qualification, staging, POC, config iteration, production argument — requires enough engineering resources that "this process generally stops somewhere before getting the workloads migrated." Aether wraps all four steps (`qualify`, `submit`, `profile`, `report`) into a single aether run command. Results and configs are stored in a SQLite history database. Supports on-prem, Amazon EMR, and Google Dataproc.
|
| 4. Aether TuneML: XGBoost model predicts optimal Spark config changes with 90% AUC ranking accuracy |
@ 43:10 |
|
Replacing rule-based formulas (QualX tunable with `aether profile`) with an XGBoost model trained on 100 NDS queries (90 train / 10 holdout), TuneML uses profiling metrics (input bytes, shuffle read/write bytes, spill rates) to predict speedup for candidate config changes. Ranking AUC ~90%: "90% of the time, the configs should lead to some speedup." Roadmap: replace XGBoost with a fine-tunable DNN and add reinforcement learning for efficient config space exploration.
|
| 5. The two critical GPU Spark configs are `sql.files.maxPartitionBytes` and `sql.shuffle.partitions` |
@ 53:09 |
|
`maxPartitionBytes` controls data per read partition; `shuffle.partitions` controls the number of shuffle tasks for joins and group-bys. "In order to take advantage of the massive parallelism, you want to have bigger and bigger batch sizes or tasks" — but too large and the job spills. Memory spill metrics in event logs are the leading indicator that shuffle tasks are oversized. These two configs drive 80% of the tuning value.
|
| 6. UDFs force a full GPU→CPU PCIe round trip — columnar→row conversion included |
@ 01:03:25 |
|
"You have to ship all the data back over PCIe to the CPU. You have to convert from those columnar batches back to row-by-row formats. You have to run the UDF, and then you have to reverse that process." The RAPIDS Accelerator cannot optimize inside a UDF — it's opaque to the query planner. Any UDF in a GPU Spark job is a performance cliff, especially for compute-heavy functions where the GPU speedup would have been highest.
|
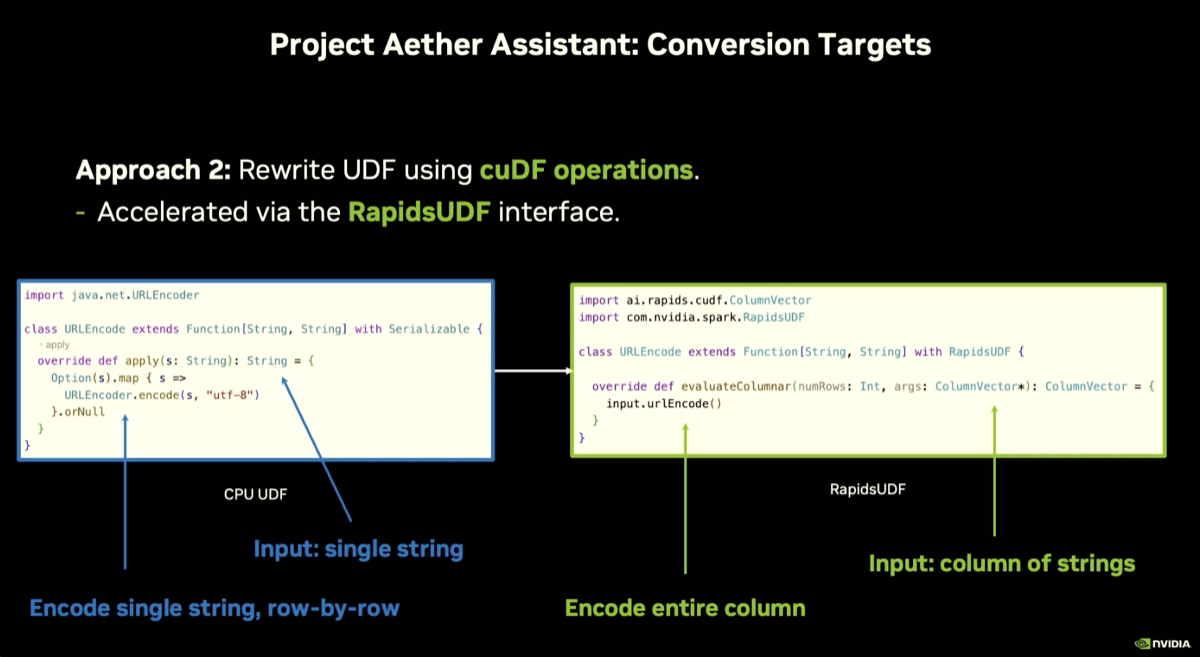
| 7. Ether Assistant: LLM rewrites CPU UDFs to GPU columnar — test generation → conversion → benchmark |
@ 01:05:18 |
|
Three-phase LLM pipeline: (1) generate unit tests for the existing CPU UDF, (2) rewrite the UDF to SQL or cuDF columnar using those tests for verification, (3) generate a synthetic dataset and benchmark both versions for speedup. Each phase is an iterative feedback loop before proceeding. The target is the RAPIDS UDF interface — a `evaluateColumnar()` override that hands the UDF GPU columnar batches directly, eliminating the PCIe round trip entirely.
|
Allison Ding · Senior Developer Advocate, Data Science, NVIDIA
NVIDIA Session overview
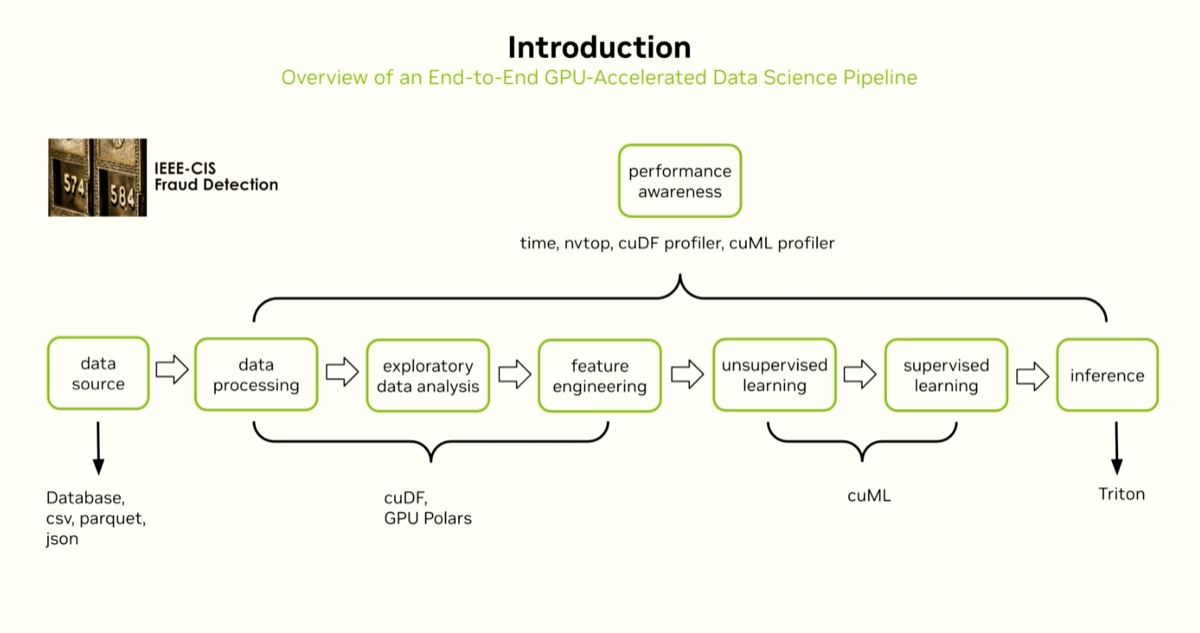
A hands-on DLI workshop walking through an end-to-end GPU-accelerated data science pipeline: data ingestion and feature engineering with cuDF/GPU Polars, unsupervised and supervised learning with cuML, and model deployment with Triton Inference Server. Uses the IEEE CIS fraud detection dataset throughout. Notebooks remain available for six months post-session.
This session covers the tools developed by NVIDIA for the full end-to-end machine learning workflow, from feature wrangling and exploration with cuDF, to accelerating various machine learning models for classification, regression, and clustering tasks with cuML, a drop-in replacement for scikit-learn, and finally how to profile and deploy the model to inference servers like Triton.
Takeaways
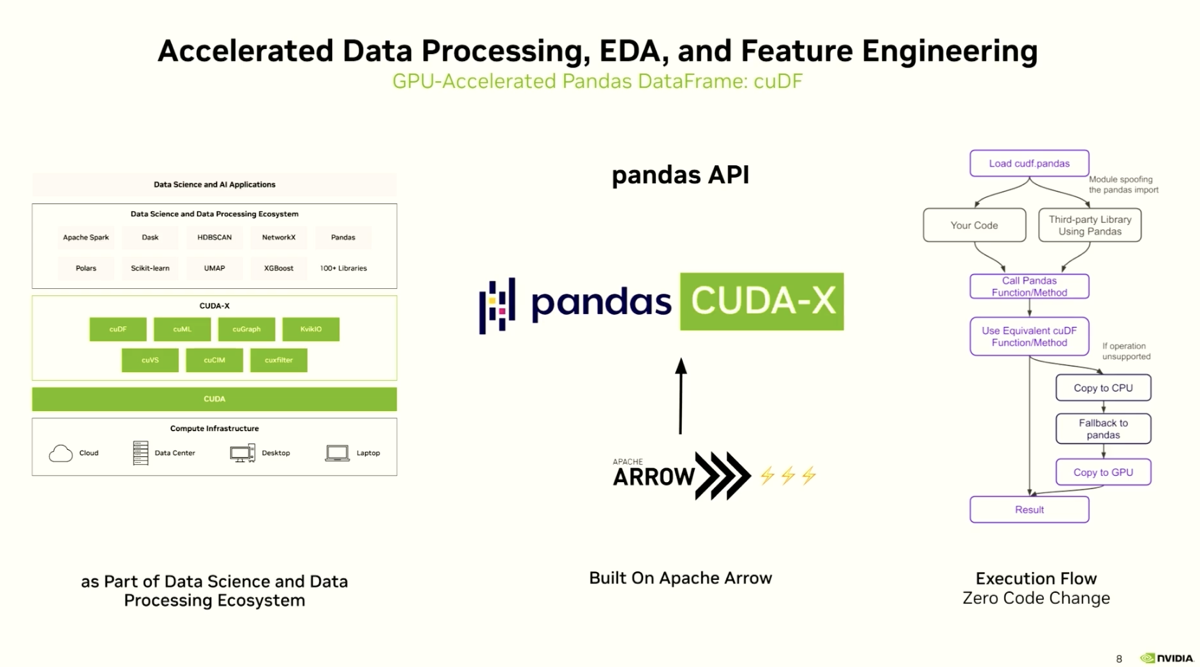
| 1. Apache Arrow is the zero-copy glue between cuDF, cuML, and GPU Polars |
@ 10:33 |
All CUDA-X libraries — cuDF, cuML, cuGraph, cuVS — share data through Apache Arrow: "Arrow provides zero copy data transfers from pandas to CUDA-X, which means the data doesn't need to be copied or converted, just a pointer is passed." This is what allows the entire pipeline to stay on GPU without marshaling overhead between steps.
|
| 2. cuDF group-by: 200× faster; merges: 130× faster on GPU |
@ 12:35 |
Key cuDF operation speedups: CSV reads ~20×, merges ~130×, group-by ~200×, select+filter ~3×. The full data processing + EDA + feature engineering pipeline on the IEEE CIS dataset runs in 43 seconds on GPU vs. 87 seconds on CPU — about 2× end-to-end, with the gains concentrated in the merge and aggregation steps.

|
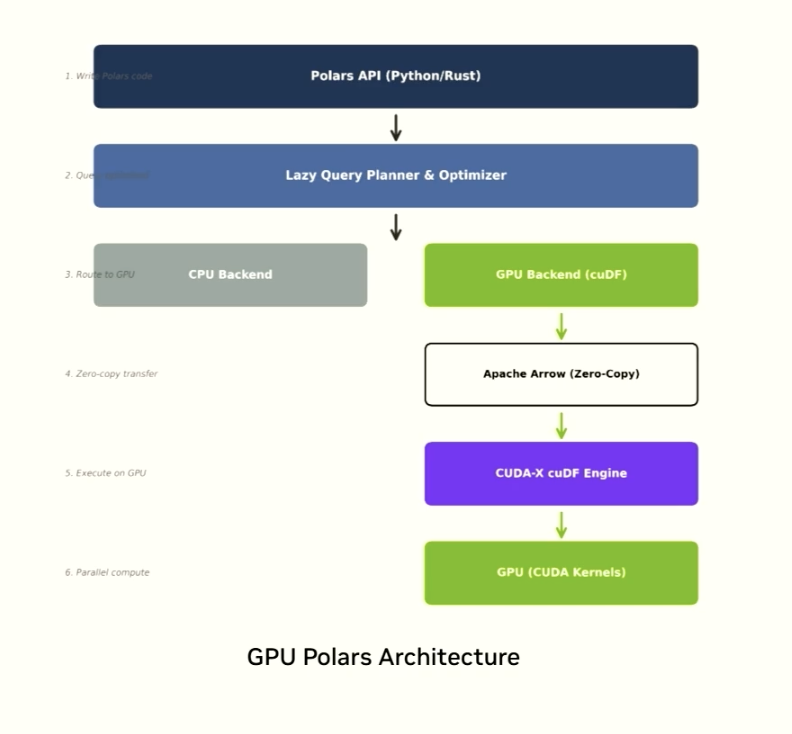
| 3. GPU Polars uses cuDF as its engine — same performance, Polars syntax |
@ 18:07 |
"GPU Polars uses CUDA-X as its execution engine" — it is not an alternative to cuDF, it is cuDF with a Polars API surface. The only change required: set `engine="gpu"` in the `.collect()` call. An email domain aggregation query runs in 78ms on CPU vs 11ms on GPU — 7×. Choose cuDF for pandas users, GPU Polars for Polars users; same hardware, same performance.
|
| 4. cuML accelerates highly parallelizable algorithms like UMAP: 40× on 2D, 20× on 3D — GPU makes it interactive |
@ 37:45 |
|
2D UMAP projection: 48 seconds on CPU, 1.3 seconds on GPU (~37×). 3D UMAP: 56 seconds → 2.8 seconds (~20×). KNN graph construction, mutual reachability distance, and gradient descent layout steps are all parallelized. At these speeds, exploratory cluster visualization becomes interactive during model development rather than a batch job.
|
| 5. Both supervised and unsupervised algorithms can be accelerated: k-means 40× faster; XGBoost training 7× faster; grid search cross-validation 4× |
@ 42:15 |
|
k-means: 4.9s CPU → 1.3s GPU, "over 40 times speedup." XGBoost single training run: 26.8s → 4.6s (7×). 5-fold cross-validation: 124s → 26.7s (~5×). 3-fold cross-validated grid search (9 XGBoost runs): 159s → 44s (4×). The acceleration applies to gradient/hessian computation, tree building, and loss evaluation — all four XGBoost phases are GPU-parallelized.
|
| 6. cuDF and cuML profilers give per-operation and line-by-line CPU vs GPU breakdown |
@ 48:08 |
Both cuDF and cuML ship with two built-in profilers: an operation-level breakdown (what ran on CPU vs GPU) and a line-by-line profiler that pinpoints bottlenecks. Common performance killers to watch for: small batch sizes that cause repeated CPU↔GPU transfers, silent CPU fallbacks for unsupported operations, and complex string operations which don't accelerate well on GPU.

|
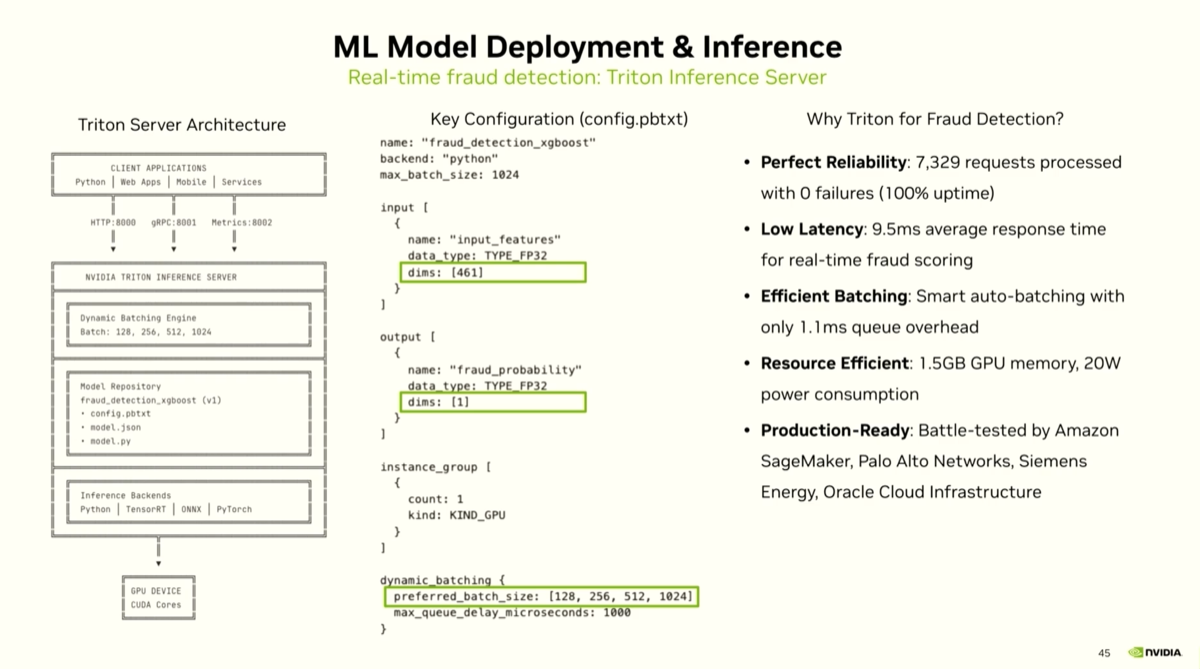
| 7. Triton Inference Server: dynamic batching from 128 to 1024, 100% success rate in testing |
@ 01:16:26 |
Triton sits between client applications and GPUs, supporting Python, TensorRT, ONNX, and PyTorch backends. For the XGBoost fraud model (461 input features, 1 output probability), dynamic batching is configured from 128 to 1024. In the workshop demo, Triton reports "100% success rate, zero failure rate." Metrics surface latency, throughput, queue efficiency, and per-GPU utilization.
|
Cross-session themes
The five sessions share a common vocabulary captured in the takeaway tags. Here is what each theme amounted to across all sessions.
| GPU scarcity and PCIe bandwidth — not compute — are the hardest constraints; CPU databases and UDFs are performance cliffs |
- [EDB] Postgres times out on agentic query loads even at modest data sizes; the database layer, not the model, is the bottleneck
- [Snap] At peak demand, GPU availability — not Spark configuration — was Snap's primary constraint
- [Zoho] Even after every I/O optimization, GPU compute is only 25% of query time; PCIe is still the bottleneck
- [Spark Workshop] Any UDF in a Spark GPU job forces a full GPU→CPU PCIe round trip plus columnar→row conversion — a performance cliff for any compute-heavy function
- [Spark Workshop] Spark on GPU sees little benefit for I/O-bound jobs or small datasets; the workload profile must be right
|
| GPU delivers 7–200× speedups across very different analytics workloads — the gains compound when the workload fits |
- [EDB] Spark RAPIDS on L40S runs TPC-DS 100× faster than standard Postgres; Blackwell adds a further 14×
- [Zoho] Zoho's Velociraptor completes all 22 TPC-H SF1k queries on a single H200 in under 2 minutes
- [Data Science Pipeline] cuDF group-by: 200× faster; merges: 130× faster; CSV reads: 20× faster on GPU
- [Data Science Pipeline] cuML k-means: 40× faster; XGBoost training: 7× faster; grid search cross-validation: 4×
- [Data Science Pipeline] UMAP dimensionality reduction: 40× on 2D, 20× on 3D — GPU makes it interactive
- [Snap] [Spark Workshop] Snap achieved 90% net cost reduction; Aether TuneML correctly ranks Spark config improvements with 90% AUC
|
| GPU reuse at near-zero incremental cost is Snap's headline finding — idle inference fleets are an untapped analytics resource |
- [Snap] Snap reused 11,000 idle inference L4s for Spark with zero new hardware spend, cutting costs by 90% and memory by 81%
- [EDB] EDB's PGAA eliminates the need for a separate analytics cluster alongside Postgres — one stack for OLTP and OLAP
- [Snap] Spark RAPIDS delivered measurable savings on Snap's non-I/O-bound jobs with minimal engineering effort
|
| Zero-code-change and graceful fallback are the dominant design principles across every session |
- [EDB] PGAA replaces only the Postgres compute back-end, leaving the SQL front-end and application layer untouched
- [Zoho] Zoho's plan conversion layer keeps the original Postgres query plan intact for OOM fallback
- [Snap] Snap's three-tier fallback (GPU GKE → CPU GKE → Dataproc) ensures no Spark job ever fails to complete
- [Data Science Pipeline] Apache Arrow zero-copy transfers between cuDF, cuML, and GPU Polars keep the full data science pipeline on GPU with no serialization overhead
- [Data Science Pipeline]
%load_ext cudf.pandas and %load_ext cuml.accel — full GPU acceleration with no code changes in notebooks
- [Spark Workshop] Project Aether wraps qualify → submit → profile → tune → validate into a single
aether run command
- [Spark Workshop] Ether Assistant's three-phase LLM pipeline (test generation → UDF rewrite → benchmark) eliminates PCIe round trips without manual rewriting
|
| Minimizing bytes that cross the PCIe bus is the central I/O strategy at every layer |
- [EDB] EDB replicates Postgres data to object storage in Apache Iceberg format, enabling columnar GPU-optimized reads
- [Zoho] Zoho's four-layer I/O stack (columnar layout + block filtering + compression + late materialization) reduces bytes per batch to a small fraction of the raw data
|
| Bandwidth is the real limiting factor; NVLink on x86 is the industry's next unlock |
- [Zoho] GPU decompression of cascaded RLE/delta columns already exceeds the PCIe Gen 4 ceiling for high-compression data
- [Zoho] Zoho is explicitly waiting for NVLink on x86; the Intel/NVIDIA NVLink fusion announcement is a direct response to PCIe being the dominant bottleneck
- [Data Science Pipeline] Arrow zero-copy means passing a pointer, not copying data — essential when group-by and merge speedups reach 130–200×
|
| ML-driven tooling closes the GPU Spark adoption gap; statistical encoding techniques compound GPU throughput gains |
- [Spark Workshop] Aether TuneML replaces hand-tuned Spark config rules with an XGBoost model trained on 100 NDS queries, achieving 90% AUC ranking accuracy
- [Spark Workshop] Ether Assistant uses an iterative LLM pipeline to rewrite CPU UDFs into GPU-native columnar code, verified by auto-generated unit tests
- [Data Science Pipeline] k-fold target encoding with smoothing (W=20–40) prevents rare-category overfitting and lifts standalone AUC from 0.589 to 0.95
- [Data Science Pipeline] GPU algorithms win in proportion to their parallelizability — UMAP and k-means benefit more than gradient boosting
|
| Partition sizing is the primary GPU Spark config lever — spill metrics are the signal |
- [Spark Workshop]
sql.files.maxPartitionBytes and sql.shuffle.partitions drive 80% of Spark GPU tuning value; memory spill metrics in event logs are the leading indicator of oversized tasks
|
| EDB packages the full agentic data stack as a sovereign, open-source, deployable-anywhere platform |
- [EDB] Lakekeeper (Iceberg catalog), LangFlow (agent authoring), NVIDIA NIMs on KServe (inference), and PGAA are packaged together — deployable on-prem, on all hyperscalers, or on custom NVIDIA hardware
|
Connect With Experts
One of the advantages of being at the conference is the opportunity to meet with NVIDIA engineers working directly on these systems, and there were several opportunities to do so with the folks involved in the accelerated data stack, which I list below for reference.
🔗 Next-Gen Data Systems: GPU Acceleration for SQL and Vector Databases
Tanmay Gujar · Developer Technology Engineer, NVIDIA
Corey Nolet · Distinguished Engineer, Unstructured Data Processing & Database Acceleration, NVIDIA
Felipe Aramburu · Distinguished Solutions Architect, NVIDIA
Manas Singh · TPM Vector Search, NVIDIA
Benjamin Karsin · Senior Developer Technology Engineer, NVIDIA
Greg Kimball · Software Engineering Manager, NVIDIA
🔗 Boost Data Science Pipelines With Accelerated Libraries
Greg Kimball · Software Engineering Manager, NVIDIA
Alexandria Barghi · Senior Software Engineer, NVIDIA
Divye Gala · Senior Software Engineer, NVIDIA
Vyas Ramasubramani · Sr. Systems Software Engineer, NVIDIA
Bobby Evans · Distinguished Software Engineer, NVIDIA
← Part 1: Technical Deep Dives