NVIDIA GTC 2025 Part 2: Deep Dive into CUDA
This is Part 2 of a 3-part series covering GTC 2025:
- Part 1: Keynote and Main Announcements
- Part 2: Deep Dive into CUDA (this post)
- Part 3: Exhibit Hall - Hardware and Robotics
Here are some of the technical highlights of my experience at the conference
CUDA C++ Workshop
On the sunday prior to the conference start, I was able to join NVIDIA CUDA engineers on a 4 hours CUDA C++ workshop, which took us through building a multi-body heat dissipation solver using the Thrust library. The workshop covered asynchronous copying, pinned memory, CUDA streams, and Nsight Systems debugging tools.
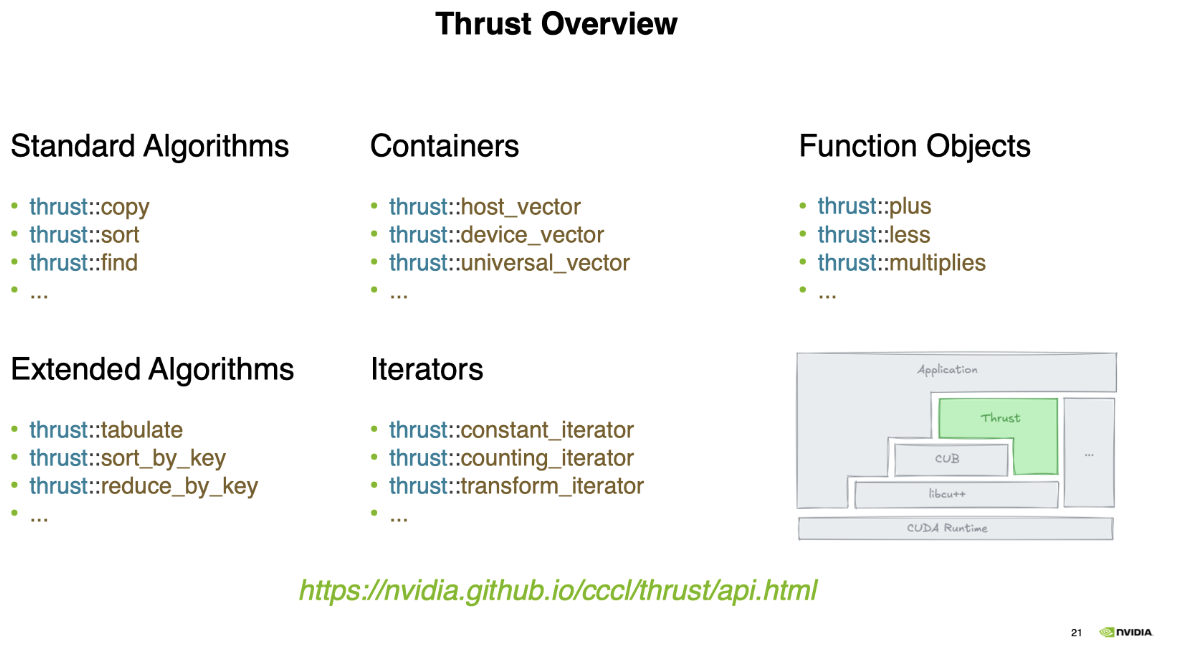
The Thrust library is not CUDA or NVIDIA specific. It works with containers that can be specified for device or host, and provides many synchronous algorithms such as sort, copy, find, tabulate, reduce_by_key and many others.
CUDA: New Features and Beyond
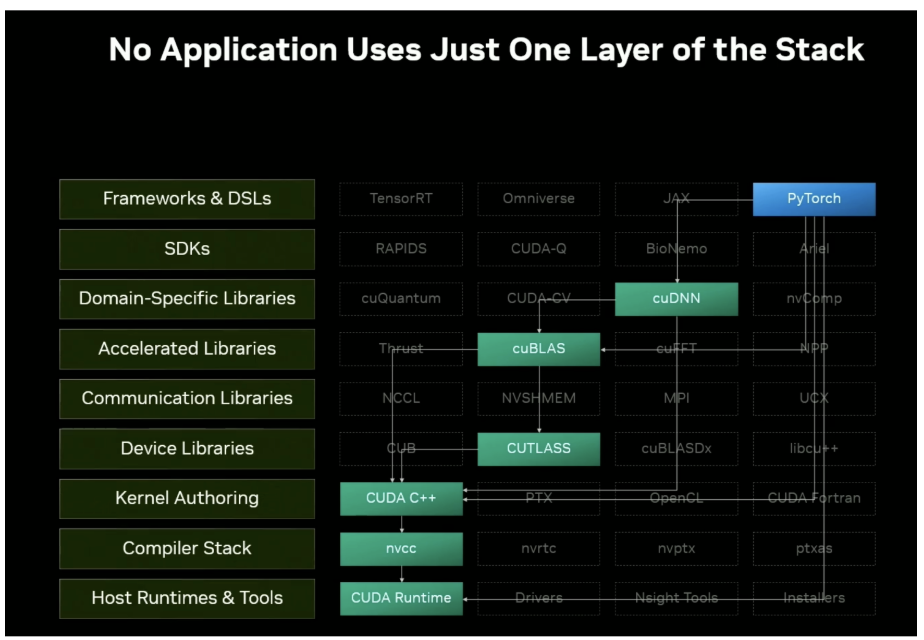
In the “CUDA: New Features and Beyond [S72383]” session, Stephen Jones reminded everyone that CUDA is a whole lot more than just its bare C++ part, with a comprehensive diagram of all the layers that are part of the CUDA ecosystem.
All the CUDA presenters had a consistent message across these sessions: Don’t write any CUDA C++ kernel code unless you absolutely have to! Instead, use the growing library of highly-optimized CUDA-X libraries.
CuTile Programming Paradigm

One big announcement was for CuTile, a new programming paradigm that extends CUDA C++ kernel approach but instead of thinking in threads, groups and clusters, developers can think in terms of tiles, promising “shorter and clearer expression of the computation.”
CUDA Developer Sessions

There were many sessions dedicated to the growing CUDA Python ecosystem, introducing new capabilities such as RAPIDS AI support as drop-in replacements for common Python tools: RAPIDS cuDF (pandas/Polars), cuML (scikit-learn), and cuPyNumeric (NumPy).
Summary of the NVIDIA CUDA-X Libraries
Compiled from https://developer.nvidia.com/gpu-accelerated-libraries
| Category | Library | Description |
|---|---|---|
| Math Libraries | cuBLAS | GPU-accelerated basic linear algebra (BLAS) library |
| cuFFT | GPU-accelerated library for Fast Fourier Transform implementations | |
| cuRAND | GPU-accelerated random number generation | |
| cuSOLVER | Dense and sparse direct solvers for computer vision, CFD, computational chemistry, and linear optimization | |
| cuSPARSE | GPU-accelerated library for sparse matrices | |
| cuTENSOR | GPU-accelerated tensor linear algebra library | |
| cuDSS | GPU-accelerated sparse direct solver | |
| Math Libraries (Python) | nvmath-python (Beta) | Open source library providing high-performance access to core mathematical operations in the NVIDIA stack through a Pythonic interface |
| Parallel Algorithm Libraries | Thrust | GPU-accelerated library of C++ parallel algorithms and data structures (uses CUB) |
| Data Processing Libraries | RAPIDS cuDF | Accelerate tabular data, including pandas and Polars, with zero code changes |
| RAPIDS cuML | Speed up ML algorithms in scikit-learn, UMAP, and HDBSCAN | |
| RAPIDS cuGraph | Accelerate NetworkX and graph analytics | |
| cuVS | GPU-accelerated vector search and clustering | |
| NeMo Curator | GPU-accelerated data curation for LLM pretraining | |
| Morpheus | GPU-accelerated data pipeline for cybersecurity | |
| GPU Direct Storage | Direct path between storage and GPU memory | |
| Image and Video Libraries | RAPIDS cuCIM | Accelerate IO, computer vision, and image processing for biomedical images |
| CV-CUDA | Open-source GPU-accelerated library for cloud-scale image processing and computer vision | |
| DALI | GPU-accelerated data augmentation and image loading for deep learning | |
| nvJPEG | GPU-accelerated JPEG decoder, encoder, and transcoder | |
| Optical Flow SDK | GPU-accelerated computation of optical flow vectors | |
| Communication Libraries | NVSHMEM | OpenSHMEM standard for GPU memory, with extensions for improved performance on GPUs |
| NCCL | Open-source library for fast multi-GPU, multi-node collective communications | |
| Deep Learning Core Libraries | NVIDIA TensorRT | High-performance deep learning inference optimizer and runtime for production deployment |
| NVIDIA cuDNN | GPU-accelerated library of primitives for deep neural networks | |
| Quantum Libraries | cuQuantum | Set of highly optimized libraries for accelerating quantum computing simulations |
| cuPQC | SDK of optimized libraries for Post Quantum Cryptography |
Continue to Part 3: Exhibit Hall - Hardware and Robotics to explore the cutting-edge hardware, liquid cooling systems, and robotics demonstrations from the exhibit hall.